Approximate time: 120 minutes
Learning objectives
- Evaluating the STAR aligner output files
- Understanding the standard alignment file (SAM/BAM) structure
- Using
samtoolsto evaluate alignment quality - Visualizing alignment quality using IGV (genome browser)
Assessing alignment quality
After running our single FASTQ file through the STAR aligner, you should have noticed a number of output files in the ~/unix_workshop/rnaseq/results/STAR directory. Let’s take a quick look at some of the files that were generated and explore the content of some of them.
$ cd ~/unix_lesson/rnaseq/results/STAR
$ ls -lh
What you should see, is that for each FASTQ file you have 5 output files and a single tmp directory. Briefly, these files are described below:
Log.final.out- a summary of mapping statistics for the sampleAligned.sortedByCoord.out.bam- the aligned reads, sorted by coordinate, in BAM formatLog.out- a running log from STAR, with information about the runLog.progress.out- job progress with the number of processed reads, % of mapped reads etc., updated every ~1 minuteSJ.out.tab- high confidence collapsed splice junctions in tab-delimited format. Only junctions supported by uniquely mapping reads are reported
Mapping statistics
Having completed the alignment, the first thing we want to know is how well did our reads align to the reference. Rather than looking at each read alignment, it can be more useful to evaluate statistics that give a general overview for the sample. One of the output files from the STAR aligner contains mapping statistics, let’s take a closer look at one of those files. We’ll use the less command which allows us to scroll through it easily:
$ less Mov10_oe_1_Log.final.out
The log file provides information on reads that 1) mapped uniquely, 2) reads that mapped to mutliple locations and 3) reads that are unmapped. Additionally, we get details on splicing, insertion and deletion. From this file the most informative statistics include the mapping rate and the number of multimappers.
- As an example, a good quality sample will have at least 75% of the reads uniquely mapped. Once values start to drop lower than 60% it’s advisable to start troubleshooting. The lower the number of uniquely mapping reads means the higher the number of reads that are mapping to multiple locations. It is best to keep this number low because multi-mappers are not included when we start counting reads
NOTE: The thresholds suggested above will vary depending on the organism that you are working with. Much of what is discussed here is in the context of working with human or mouse data. For example, 75% of mapped reads holds true only if the genome is good or mature. For badly assembled genomes we may not observe a high mapping rate, even if the actual sequence sample is good.
Exercise
Using the less command take a look at Mov10_oe_1_Log.final.out and answer the following questions:
- How many reads map to more than 10 locations on the genome?
- How many reads are unmapped due to read length?
- What is the average mapped length per read?
Other quality checks
In addition to the aligner-specific summary we can also obtain quality metrics using tools like Qualimap or RNASeQC. These tools examine sequencing alignment data according to the features of the mapped reads and their genomic properties and provide an overall view of the data that helps to to the detect biases in the sequencing and/or mapping of the data.The input can be one or more BAM files and the output consists of HTML or PDF reports with useful figures and tab delimited files of metrics data.
We will not be performing this step in the workshop, but we describe some of the features below to point out things to look for when assessing alignment quality of RNA-seq data:
- Reads genomic origin: Even if you have high genomic mapping rate for all samples, check to see where the reads are mapping. Ensure that there is not an unusually high number of reads mapping to intronic regions (~30% expected) and fewer than normally observed mapping to exons (~55%). A high intronic mapping suggests possible genomic DNA contamination and/or pre-mRNA.
- Ribosomal RNA (rRNA) constitutes a large majority of the RNA species in any total RNA preparation. Despite depletion methods, you can never achieve complete rRNA removal. Even with Poly-A enrichment a small percentage of ribosomal RNA can stick to the enrichment beads non-specifically. Excess ribosomal content (> 2%) will normally have to be filtered out so that differences in rRNA mapped reads across samples do not affect alignment rates and skew subsequent normalization of the data.
- Transcript coverage and 5’-3’ bias: assesing the affect on expression level and on levels of transcript GC content
- Junction analysis: analysis of junction positions in spliced alignments (i.e known, partly known, novel)
- Strand specificity: assess the performance of strand-specific library construction methods. The percentage of sense-derived reads is given for each end of the read pair. A non-strand-specific protocol would give values of 50%/50%, whereas strand-specific protocols typically yield 99%/1% or 1%/99% for this metric.
NOTE: If interested in using Qualimap, we have materials available that you can walk through.
Alignment file format: SAM/BAM
The output we requested from the STAR aligner (using the appropriate parameters) is a BAM file. By default STAR will return a file in SAM format. BAM is a binary, compressed version of the SAM file, also known as Sequence Alignment Map format. The SAM file, introduced is a tab-delimited text file that contains information for each individual read and its alignment to the genome. While we will go into some features of the SAM format, the paper by Heng Li et al provides a lot more detail on the specification.
The file begins with a header, which is optional. The header is used to describe source of data, reference sequence, method of alignment, etc., this will change depending on the aligner being used. Each section begins with character ‘@’ followed by a two-letter record type code. These are followed by two-letter tags and values. Example of some common sections are provided below:
@HD The header line
VN: format version
SO: Sorting order of alignments
@SQ Reference sequence dictionary
SN: reference sequence name
LN: reference sequence length
SP: species
@PG Program
PN: program name
VN: program version
Following the header is the alignment section. Each line that follows corresponds to alignment information for a single read. Each alignment line has 11 mandatory fields for essential mapping information and a variable number of other fields for aligner specific information.
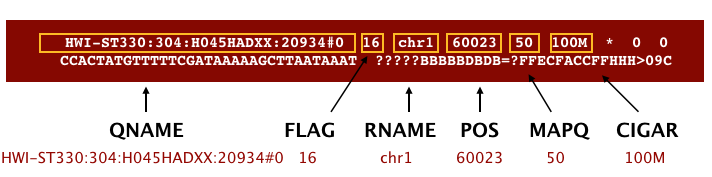
An example read mapping is displayed above. Note that the example above spans two lines, but in the file it is a single line. Let’s go through the fields one at a time.
We are going to go through this out of order. Let’s start with QNAME which is the read name. RNAME is the reference sequence name, which is ‘chr1’ in this example. POS refers to the 1-based leftmost position of the alignment. MAPQ is giving us the alignment quality, the scale of which will depend on the aligner being used.
Next, we the FLAG. The FLAG value represents various things about the alignment. that is displayed can be translated into information about the mapping.
| Flag | Description |
|---|---|
| 1 | read is mapped |
| 2 | read is mapped as part of a pair |
| 4 | read is unmapped |
| 8 | mate is unmapped |
| 16 | read reverse strand |
| 32 | mate reverse strand |
| 64 | first in pair |
| 128 | second in pair |
| 256 | not primary alignment |
| 512 | read fails platform/vendor quality checks |
| 1024 | read is PCR or optical duplicate |
- For a given alignment, each of these flags are either on or off indicating the condition is true or false.
- The
FLAGis a combination (additive) of all of the individual flags (from the table above) that are true for the alignment - The beauty of the flag values is that any combination of flags can only result in one sum.
In our example we have a number that exist in the table, making it relatively easy to translate. But suppose our read alignment has a flag of 163; this means it is some combination of the list above and you can find out what this mean using various online tools like this one from Picard**
CIGAR is a sequence of letters and numbers that represent the edits or operations required to match the read to the reference. The letters are operations that are used to indicate which bases align to the reference (i.e. match, mismatch, deletion, insertion), and the numbers indicate the associated base lengths for each ‘operation’. This is used by some downstream tools to quickly assess the alignment.
Now to the remaning fields in our SAM file:
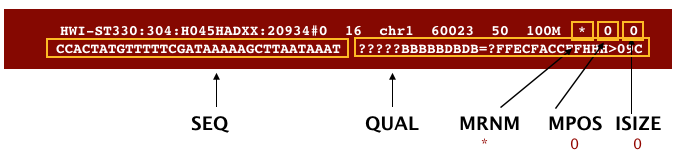
The next three fields are more pertinent to paired-end data. MRNM is the mate reference name. MPOS is the mate position (1-based, leftmost). ISIZE is the inferred insert size.
Finally, you have the data from the original FASTQ file stored for each read. That is the raw sequence (SEQ) and the associated quality values for each position in the read (QUAL).
samtools
SAMtools is a tool that provides alot of functionality in dealing with SAM files. SAMtools utilities include, but are not limited to, viewing, sorting, filtering, merging, and indexing alignments in the SAM format. In this lesson we will explore a few of these utilities on our alignment files. To use this we need to load the module.
$ module load samtools/1.3.1
Viewing the SAM file
Now that we have learned so much about the SAM file format, let’s use samtools to take a quick peek at our own files. The output we had requested from STAR was a BAM file. The problem is the BAM file is binary and not human-readable. Using the view command within samtools we can easily convert the BAM into something that we can understand. You will be returned to screen the entire SAM file, and so we can either write to file, or pipe this to the less command so we can scroll through it.
We will do the latter (since we don’t really need it for downstream analysis) and scroll through the SAM file (using the up and down arrows) to see how the fields correspond to what we expected. Adding the -h flag allows to also view the header.
$ samtools view -h Mov10_oe_1_Aligned.sortedByCoord.out.bam | less
Filtering the SAM file
Now we know that we have all of this information for each of the reads – wouldn’t it be useful to summarize and filter based on selected criteria? Suppose we wanted to set a threshold on mapping quality. For example, we want to know how many reads aligned with a quality score higher than 30. To do this, we can combine the
viewcommand with additional flagsq 30and-c(to count):$ samtools view -q 30 -c Mov10_oe_1_Aligned.sortedByCoord.out.bamHow many of reads have a mapping quality of 30 or higher?
We can also apply filters to select reads based on where they fall within the
FLAGcategories. Remember that the bitwise flags are like boolean values. If the flag exists, the statement is true. Similar to when filtering by quality we need to use thesamtools viewcommand, however this time use the-For-fflags.
-f- to find the reads that agree with the flag statement-F- to find the reads that do not agree with the flag statement## This will tell us how many reads are unmapped $ samtools view -f 4 -c Mov10_oe_1_Aligned.sortedByCoord.out.bam ## This should give us the remaining reads that do not have this flag set (i.e reads that are mapped) $ samtools view -F 4 -c Mov10_oe_1_Aligned.sortedByCoord.out.bam
Indexing the BAM file
To perform some functions (i.e. subsetting, visualization) on the BAM file, an index is required, but this index is different from the genomic index we worked with in the last lesson. In order to index a BAM file, it must first be sorted in one way or another. samtools can perform this sorting, however in our case STAR performed a coordinate sort for us because of a parameter we had specified.
To index the BAM file we use the index command:
$ samtools index Mov10_oe_1_Aligned.sortedByCoord.out.bam
This will create an index in the same directory as the BAM file, which will be identical to the input file in name but with an added extension of .bai.
Visualization
Another method for assessing the quality of your alignment is to visualize the alignment using a genome browser. For this course we will be using the Integrative Genomics Viewer (IGV) from the Broad Institute. You should already have this downloaded on your laptop. IGV is an interactive tool which allows exploration of large, integrated genomic datasets. It supports a wide variety of data types, including array-based and next-generation sequence data, and genomic annotations, which facilitates invaluable comparisons.
Transfer files
In order to visualize our alignments we will first need to move over the relevant files. We previously used FileZilla to transfer files from O2 to your laptop. However, there is another way to do so using the command line interface. Similar to the cp command to copy there is a command that allows you to securely copy files between computers. The command is called scp and allows files to be copied to, from, or between different remote computers.
First, identify the location of the origin file you intend to copy, followed by the destination of that file. Since the origin file is located on O2, this requires you to provide remote host and login information.
The following 2 files need to be moved from O2 to your local machine,
Mov10_oe_1_Aligned.sortedByCoord.out.bam,
Mov10_oe_1_Aligned.sortedByCoord.out.bam.bai
$ scp user_name@o2.hms.harvard.edu:/home/$USER/unix_lesson/rnaseq/results/Mov10_oe_1_Aligned.sortedByCoord.out.bam* /path/to/directory_on_laptop
Visualize
- Start IGV You should have this previously installed on your laptop
- Load the Human genome (hg19) into IGV using the dropdown menu at the top left of your screen. Note: there is also an option to “Load Genomes from File…” under the “Genomes” pull-down menu - this is useful when working with non-model organisms
- Load the .bam file using the “Load from File…“ option under the “File” pull-down menu. IGV requires the .bai file to be in the same location as the .bam file that is loaded into IGV, but there is no direct use for that file.
- Type MOV10 into the search bar.
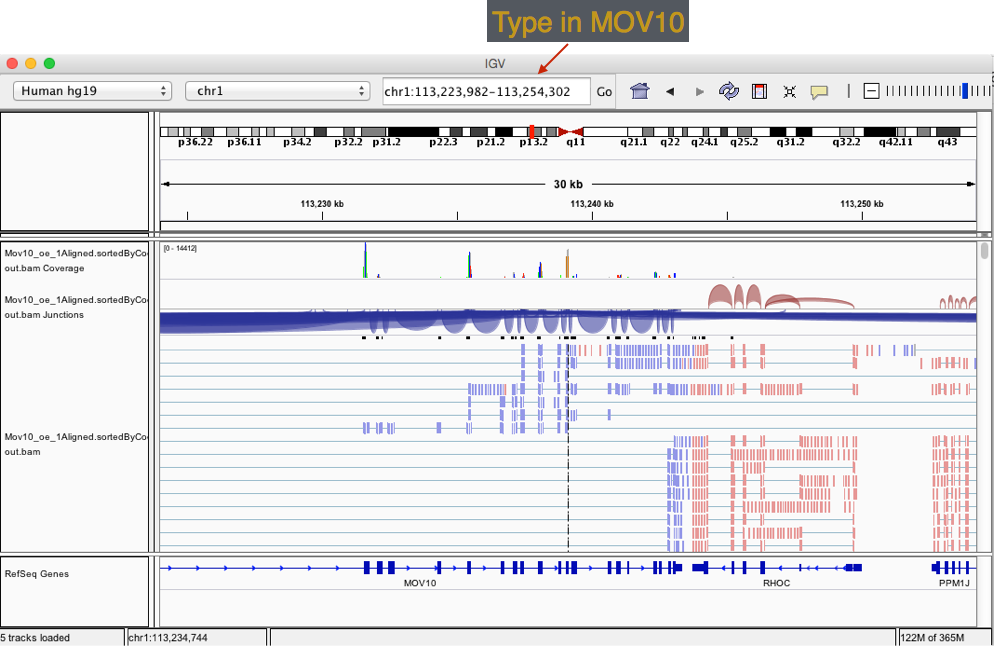
Exercise
Take a look at a few genes by typing into the search bar. Anything interesting about PPM1J and PTPN22?
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.