Approximate time: 50 minutes
Learning Objectives:
- Brief explanation about SAM file
- Running an alignment tool to generate BAM files
- Running Qualimap to compute metrics on alignment files
Quality Control for Alignment Data
After running Salmon, we now have transcript-level abundance estimates for each of our samples. When Salmon performs the quasi-alignment, internally the algorithm knows the location(s) to which each read is assigned, however this information is not shared with the user. In order for us to make an assessment on the quality of the mapping we need genomic coordinate information for where each read maps. Since this is not part of the Salmon output we will need to use a genome alignment tools to generate a BAM file. The BAM file will be used as input to a tool called Qualimap which computes various quality metrics such as DNA or rRNA contamination, 5’-3’ biases, and coverage biases.
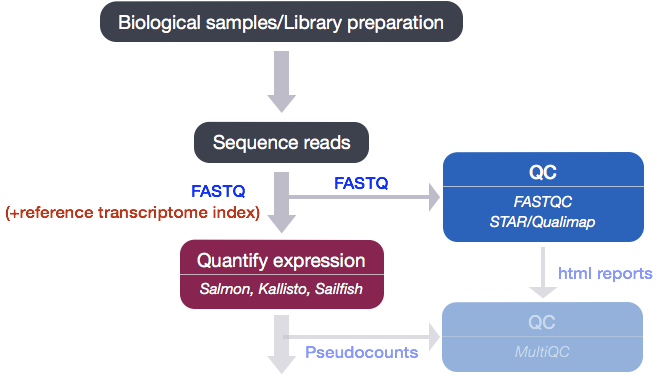
Alignment file format: SAM/BAM
The Sequence Alignment Map format (SAM) file is a tab-delimited text file that contains all information from the FASTQ file, with additional fields containing alignment information for each read. Specifically, we can obtain the genomic coordinates of where each read maps to in the genome and the quality of that mapping. A BAM file is the binary, compressed version of the SAM file. It is significantly smaller in size and is usually the file format requested for by downstream tools that require alignment data as input. The paper by Heng Li et al provides a lot more detail on the specification.
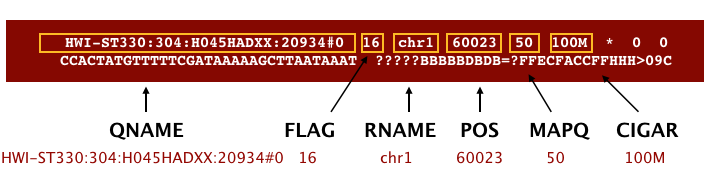
Creating a BAM file
To generate a BAM file we need to map our reads to the genome. The alignment process consists of choosing an appropriate reference genome to map our reads against and performing the read alignment using one of several splice-aware alignment tools such as STAR or HISAT2. The choice of aligner is often a personal preference and also dependent on the computational resources that are available to you.
STAR Aligner
To determine where on the human genome our reads originated from, we will align our reads to the reference genome using STAR (Spliced Transcripts Alignment to a Reference). STAR is an aligner designed to specifically address many of the challenges of RNA-seq data mapping using a strategy to account for spliced alignments. We will not go into detail about how STAR works, but if you are interested in undertanding the alignment strategy we have some materials linked here.
NOTE: Until recently, the standard approach for RNA-seq analysis has been to map our reads using a splice-aware aligner (i.e STAR) and then use the resulting BAM files as input to counting tools like featureCounts and htseq-count to obtain our final expression matrix. The field has now moved towards using lightweight alignment tools like Salmon as standard practice, and so we only use STAR for generating a BAM file. If you are interested in knowing more about the standard approach we have some materials linked here.
To get started with this lesson, start an interactive session with 6 cores and 8G of memory:
$ srun --pty -p interactive -t 0-12:00 -c 6 --mem 8G --reservation=HBC /bin/bash
You should have a directory tree setup similar to that shown below. It is best practice to have all files you intend on using for your workflow present within the same directory.
rnaseq
├── logs
├── meta
├── raw_data
│ ├── Irrel_kd_1.subset.fq
│ ├── Irrel_kd_2.subset.fq
│ ├── Irrel_kd_3.subset.fq
│ ├── Mov10_oe_1.subset.fq
│ ├── Mov10_oe_2.subset.fq
│ └── Mov10_oe_3.subset.fq
├── results
└── scripts
To use the STAR aligner, load the module:
$ module load gcc/6.2.0 star/2.7.0a
Similar to Salmon, aligning reads using STAR is a two step process:
- Create a genome index
- Map reads to the genome
A quick note on shared databases for human and other commonly used model organisms. The O2 cluster has a designated directory at
/n/groups/shared_databases/in which there are files that can be accessed by any user. These files contain, but are not limited to, genome indices for various tools, reference sequences, tool specific data, and data from public databases, such as NCBI and PDB. So when using a tool that requires a reference of sorts, it is worth taking a quick look here because chances are it’s already been taken care of for you.$ ls -l /n/groups/shared_databases/igenome/
Creating a genome index
For this workshop we are using reads that originate from a small subsection of chromosome 1 (~300,000 reads) and so we are using only chr1 as the reference genome from hg38 without the alternative alleles.
The basic options to generate genome indices using STAR are as follows:
--runThreadN: number of threads--runMode: genomeGenerate mode--genomeDir: /path/to/store/genome_indices--genomeFastaFiles: /path/to/FASTA_file--sjdbGTFfile: /path/to/GTF_file--sjdbOverhang: readlength -1
NOTE: In case of reads of varying length, the ideal value for
--sjdbOverhangis max(ReadLength)-1. In most cases, the default value of 100 will work similarly to the ideal value.
The final command to create an index can be found in the job submission script we have linked here. We have generated the genome indices for you, so that we don’t get held up waiting on the generation of the indices. The index can be found in the /n/groups/hbctraining/intro_rnaseq_hpc/reference_data_ensembl38/ensembl38_STAR_index/ directory.
NOTE: By default the latest human genome build, GRCh38, contains information about alternative alleles for various locations on the genome. If using this version of the GRCh38 genome then it is advisable to use the HISAT2 aligner as it is able to utilize this information during the alignment. There is a version of GRCh38 available that does not have these alleles represented, which is the appropriate version to use with STAR. This is because STAR does not have the functionality to appropriately deal with the presence of alternate alleles.
Aligning reads
After you have the genome indices generated, you can perform the read alignment.
Create an output directory for our alignment files:
$ cd ~/rnaseq/raw_data
$ mkdir ../results/STAR
For now, we’re going to work on just one sample to set up our workflow. To start we will use the first replicate in the Mov10 over-expression group, Mov10_oe_1.subset.fq. Details on STAR and its functionality can be found in the user manual; we encourage you to peruse through to get familiar with all available options.
The basic options for aligning reads to the genome using STAR are:
--runThreadN: number of threads / cores--readFilesIn: /path/to/FASTQ_file--genomeDir: /path/to/genome_indices_directory--outFileNamePrefix: prefix for all output files
Listed below are additional parameters that we will use in our command:
--outSAMtype: output filetype (SAM default)--outSAMunmapped: what to do with unmapped reads
NOTE: Default filtering is applied in which the maximum number of multiple alignments allowed for a read is set to 10. If a read exceeds this number there is no alignment output. To change the default you can use
--outFilterMultimapNmax, but for this lesson we will leave it as default. Also, note that “STAR’s default parameters are optimized for mammalian genomes. Other species may require significant modifications of some alignment parameters; in particular, the maximum and minimum intron sizes have to be reduced for organisms with smaller introns” [1].
The full command is provided below for you to copy paste into your terminal. If you want to manually enter the command, it is advisable to first type out the full command in a text editor (i.e. Sublime Text or Notepad++) on your local machine and then copy paste into the terminal. This will make it easier to catch typos and make appropriate changes.
$ STAR --genomeDir /n/groups/hbctraining/intro_rnaseq_hpc/reference_data_ensembl38/ensembl38_STAR_index/ \
--runThreadN 6 \
--readFilesIn Mov10_oe_1.subset.fq \
--outFileNamePrefix ../results/STAR/Mov10_oe_1_ \
--outSAMtype BAM SortedByCoordinate \
--outSAMunmapped Within \
--outSAMattributes Standard
After running our single FASTQ file through the STAR aligner, you should have a number of output files in the ~/rnaseq/results/STAR directory. Let’s take a quick look at some of the files that were generated and explore their content.
$ cd ~/rnaseq/results/STAR
$ ls -lh
What you should see, is that for each FASTQ file you have 5 output files and a single tmp directory. Briefly, these files are described below:
Log.final.out- a summary of mapping statistics for the sampleAligned.sortedByCoord.out.bam- the aligned reads, sorted by coordinate, in BAM formatLog.out- a running log from STAR, with information about the runLog.progress.out- job progress with the number of processed reads, % of mapped reads etc., updated every ~1 minuteSJ.out.tab- high confidence collapsed splice junctions in tab-delimited format. Only junctions supported by uniquely mapping reads are reported
Assessing Alignment Quality
Alignment data files frequently contain biases that are introduced by sequencing technologies, during sample preparation, and/or the selected mapping algorithm. Therefore, one of the fundamental requirement during analysis of these data is to perform quality control. In this way, we get an idea of how well our reads align to the reference and how well data fit with the expected outcome.
Mapping statistics
Different alignment tools will output a summary of the mapping in different ways. For STAR, the Log.final.out file contains mapping statistics. Rather than looking at each read alignment, it can be more useful to evaluate statistics that give a general overview for all reads within a sample. Let’s use the less command to scroll through it:
$ less Mov10_oe_1_Log.final.out
The log file provides information on reads that 1) mapped uniquely, 2) reads that mapped to mutliple locations and 3) reads that are unmapped. Additionally, we get details on splicing, insertion and deletion. From this file the most informative statistics include the mapping rate and the number of multimappers.
Qualimap
In addition to the aligner-specific summary, we can also obtain quality metrics using tools like Qualimap, a Java application that aims to facilitate the quality-control analysis of mapping data.
The Qualimap tool takes BAM files as input and explores the features of mapped reads and their genomic properties. It provides an overall view of the data quality in an HTML report format. The reports are comprehensive with mapping statistics summarized along with useful figures and tab delimited files of metrics data. We will run Qualimap on a single sample, and then take a detailed look at the report and metrics in comparison to what we would expect for good data.
To run Qualimap, change directories to the rnaseq folder and make a qualimap folder inside the results directory:
$ cd ~/rnaseq
$ mkdir -p results/qualimap
By default, Qualimap will try to open a GUI to run Qualimap, so we need to run the unset DISPLAY command:
$ unset DISPLAY
We also need to add the location of the Qualimap tool to our PATH variable:
$ export PATH=/n/app/bcbio/dev/anaconda/bin:$PATH
Now we can run Qualimap on our aligned data. There are different tools or modules available through Qualimap, and the documentation details the tools and options available. We are interested in the rnaseq tool. To see the arguments available for this tool we can search the help:
$ qualimap rnaseq --help
We will be running Qualimap with the following specifications:
-outdir: output directory for html report-a: Counting algorithm - uniquely-mapped-reads(default) or proportional (each multi-mapped read is weighted according to the number of mapped locations)-bam: path/to/bam/file(s)-p: Sequencing library protocol - strand-specific-forward, strand-specific-reverse or non-strand-specific (default)-gtf: path/to/gtf/file - needs to match the genome build and GTF used in alignment--java-mem-size=: set Java memory
$ qualimap rnaseq \
-outdir results/qualimap/Mov10_oe_1 \
-a proportional \
-bam results/STAR/Mov10_oe_1_Aligned.sortedByCoord.out.bam \
-p strand-specific-reverse \
-gtf /n/groups/hbctraining/intro_rnaseq_hpc/reference_data_ensembl38/Homo_sapiens.GRCh38.92.1.gtf \
--java-mem-size=8G
The Qualimap report should be present in our results/qualimap directory. To view this report we would need to transfer it over to our local computers. However, this report was generated on a subset of data on chromosome 1; to get a better idea of the metrics we can take a look at the report of the full dataset for Mov_oe_1, which is available in this zipped folder.
Read alignment summary
The first few numbers listed here are similar to what we find in the mapping statistics log file from STAR. Qualimap also computes counts by assigning reads to genes and reports associated statistics. For example, the number of reads aligned to genes, number of ambiguous alignments (belong to several genes) and number of alignments without any feature (intronic and intergenic).
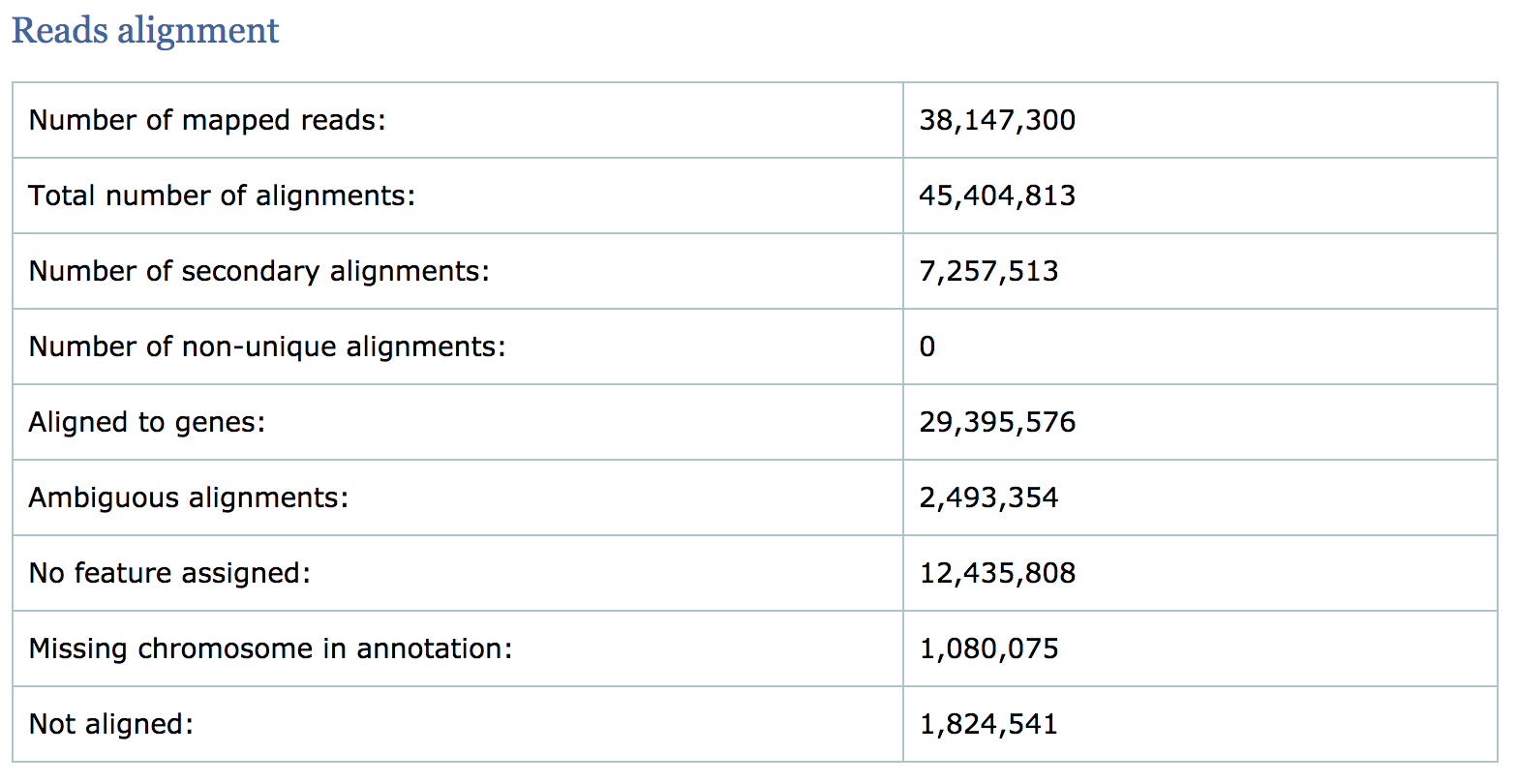
- The percentage of mapped reads is a global indicator of the overall sequencing accuracy. We expect between 70-90% of reads to be mapped for the human genome.
- Expect a small fraction of reads to be mapping equally well to multiple regions in the genome (‘multi-mapping reads’).
- The count related metrics are not as relevant to us since we have quantified with Salmon at the transcript level.
Reads genomic origin
This section reports how many alignments fall into exonic, intronic and intergenic regions along with a number of intronic/intergenic alignments overlapping exons. Exonic region includes 5’UTR,protein coding region and 3’UTR region. This information is summarized in table in addition to a pie chart as shown below.
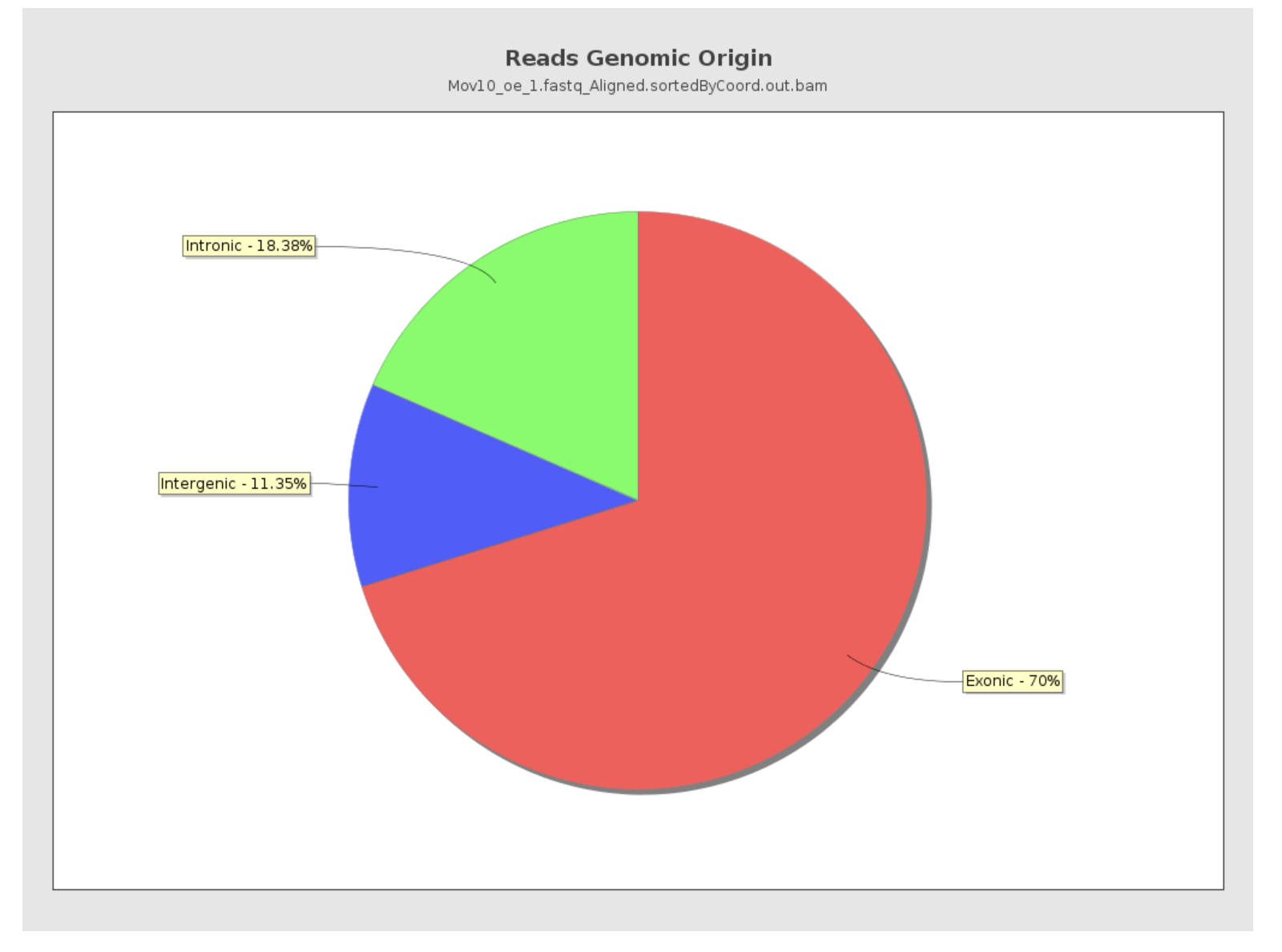
- Even if you have high genomic mapping rate for all samples, check to see where the reads are mapping. Expect a high proportion of reads mapping to exonic regions (> 60%) and lower intronic mapping rates (20 -30%).
- A higher intronic mapping rate is expected for rRNA removal compared to polyA selection. The intronic reads likely originate from immature transcripts which include either full-length pre-mRNA molecules or nascent transcripts where the RNA polymerase has not yet attached to the 3′ end of the gene.
- A roughly equal distribution of reads mapping to intronic, exonic and intergenic regions suggests that there is DNA contamination.
- Ribosomal RNA (rRNA) constitutes a large majority of the RNA species in any total RNA preparation. Despite depletion methods, you can never achieve complete rRNA removal. Even with Poly-A enrichment a small percentage of ribosomal RNA can stick to the enrichment beads non-specifically. Excess ribosomal content (> 2%) will normally have to be filtered out so that differences in rRNA mapped reads across samples do not affect alignment rates and skew subsequent normalization of the data.
Transcript coverage profile
The profile provides ratios between mean coverage at the 5’ region, the 3’ region and the whole transcript. Coverage plots are generated for all genes total, and also for the 500 highest-expressed and 500 lowest-expressed genes separately.
- 5’ bias: the ratio between mean coverage at the 5’ region (first 100bp) and the whole transcript
- 3’ bias: is the ratio between mean coverage at the 3’ region (last 100bp) and the whole transcript
- 5’-3’ bias: is the ratio between both biases.
![]()
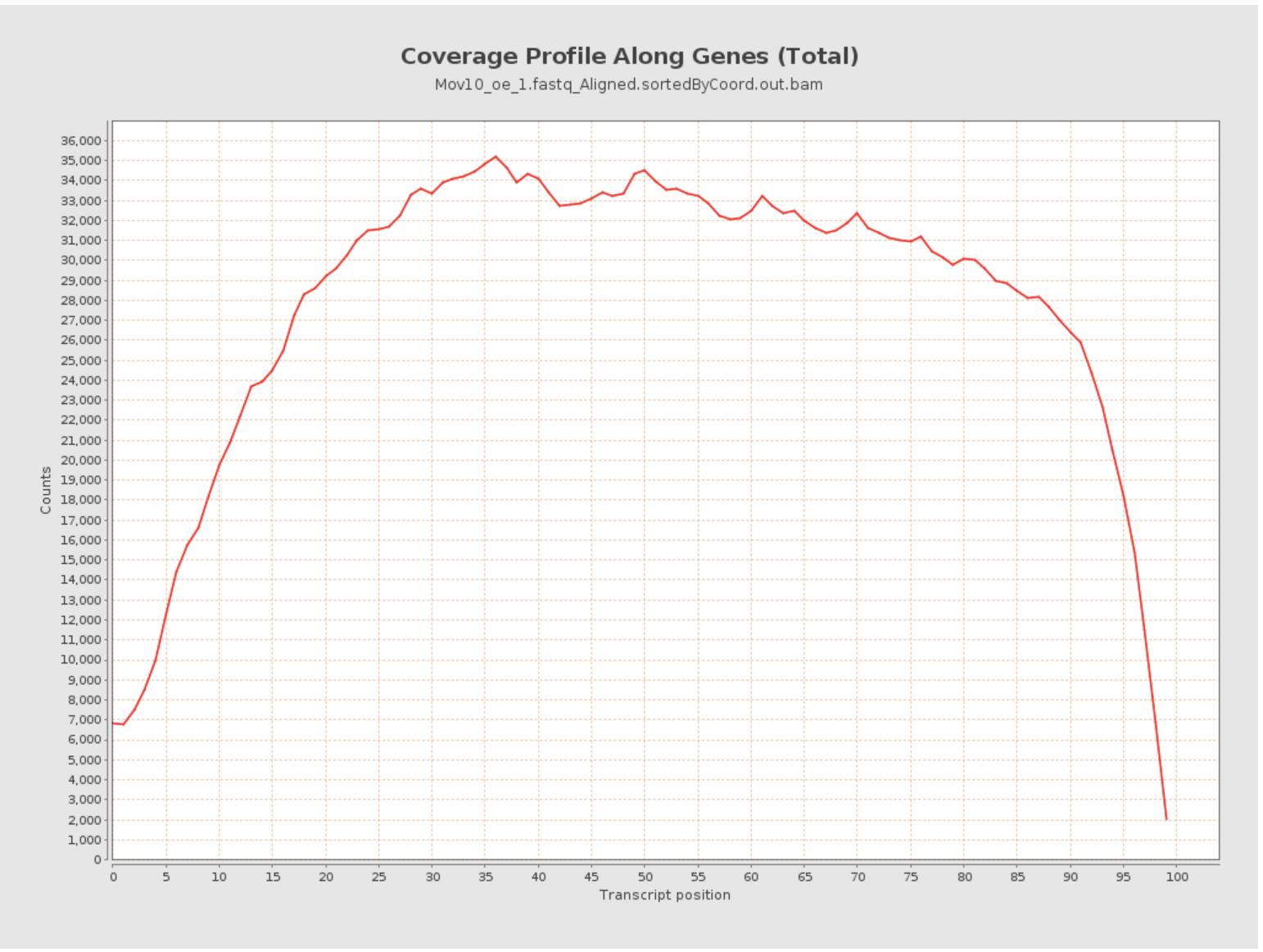
- In a perfect sequencing experiment you would expect to see a 5’-3’ bias ratio of 1 with low coverage at both ends of the transcript. This would suggest no bias is present.
- It is well-documented that libraries prepared with polyA selection can lead to high expression in 3’ region (3’ bias). At least one study shows the reverse effect for rRNA removal.
- If reads primarily accumulate at the 3’ end of transcripts in poly(A)-selected samples, this might indicate low RNA quality in the starting material.
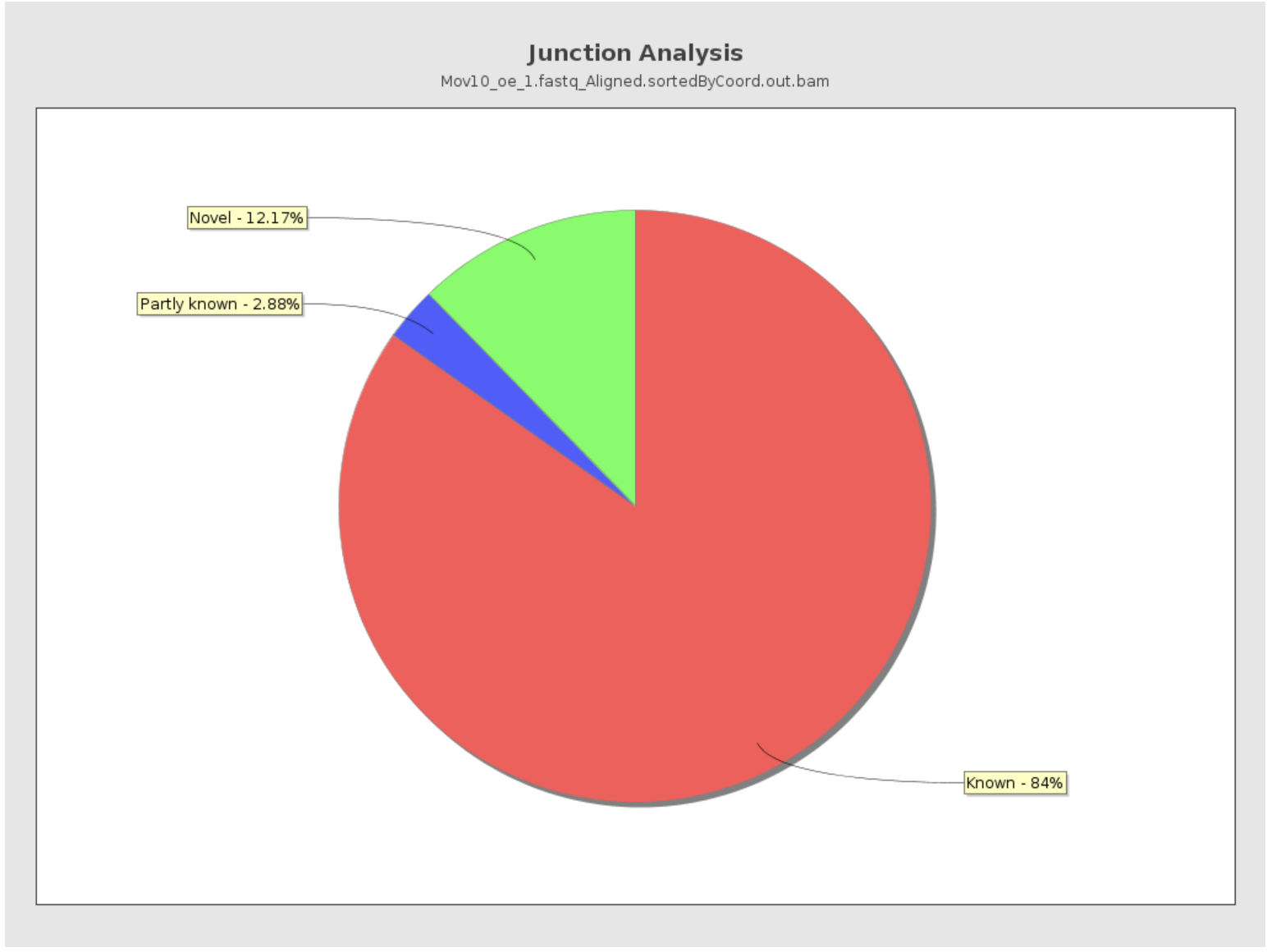
Junction Analysis
Qualimap also reports the total number of reads mapping to splice junctions and the 10 most frequent junction rates. The pie chart shows analysis of junction positions in spliced alignments.
- Known category represents percentage of alignments where both junction sides are known.
- Partly known represents alignments where only one junction side is known.
- All other alignments with junctions are marked as Novel.
Other tools like RNASeQC will plot figures that can help evaluate GC content bias. This is also an important aspect of QC, as low/high GC content regions will tend to have low coverage.
Taken together, these metrics give us some insight into the quality of our samples and help us in identifying any biases present in our data. The conclusions derived from these QC results may indicate that we need to correct for these biases and so you may want to go back and modify the parameters for Salmon (mapping) accordingly.
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.