Contributors: Meeta Mistry, Jihe Liu, Radhika Khetani, Mary Piper, Will Gammerdinger
Approximate time: 60 minutes
Learning Objectives
- Describe the different components of the MACS2 peak calling algorithm
- Describe the parameters involved in running MACS2
- List and describe the output files from MACS2
Peak Calling
Peak calling, the next step in our workflow, is a computational method used to identify areas in the genome that have been enriched with aligned reads as a consequence of performing a ChIP-sequencing experiment.
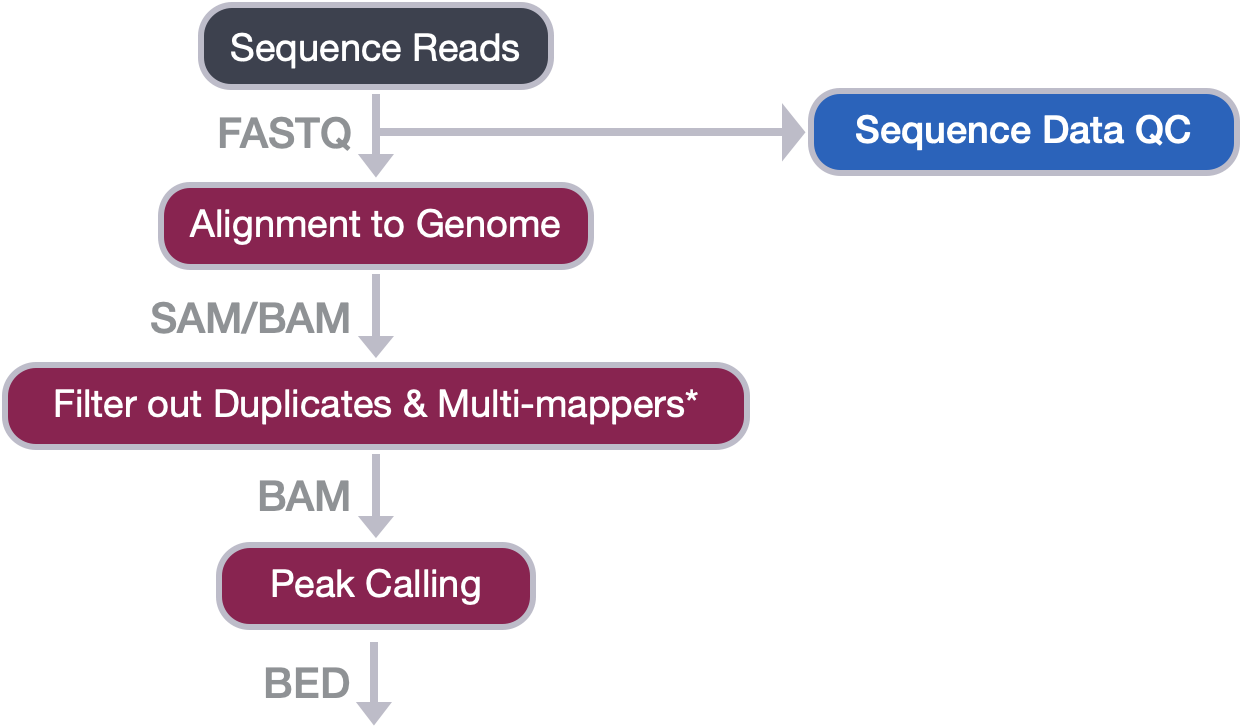
ChIP-seq
For ChIP-seq experiments, what we observe from the alignment files is a strand asymmetry with read densities on the +/- strand, centered around the binding site. The 5’ ends of the selected fragments will form groups on the positive- and negative-strand. The distributions of these groups are then assessed using statistical measures and compared against background (input or IgG samples) to determine if the site of enrichment is likely to be a real binding site.
![]()
Image source: Wilbanks and Faccioti, PLoS One 2010
A common question is how do we navigate the myriad of options for peak calling, and how do we determine which is best for our data? A study by Wilbanks & Facciotti (2010). PLoS ONE, conducted an evaluation of algorithm performance in ChIP-Seq peak detection of 12 different peak callers. The conclusion was that while there was some consensus among them, the number of peaks identified by each was highly variable. The choice of caller is also dependent on your data and the protein under study. A commonly used tool for identifying binding sites is named Model-based Analysis of ChIP-seq (MACS), and is what we will be using in this workshop.
CUT&RUN
While standard ChIP-seq peak callers like MACS2 are commonly used for calling peaks from CUT&RUN data, there are concerns that the low read depths and low background levels can render standard peak callers vulnerable to increased false postives. To address this, the Henikoff group has developed a tool called SEACR (Sparse Enrichment Analysis for CUT&RUN) which provides an analysis strategy that uses the global distribution of background signal to calibrate a simple threshold for peak calling.
How does it work?
- Data are first parsed into signal blocks representing segments of continuous, nonzero read depth by fragment spanning read pairs.
- Signal in each block is calculated by summing read counts.
- Empirically determine a threshold to filter
- Plot proportion of signal blocks in Target / IgG (y-axis) is used to identify the threshold value at which the percentage of Target versus IgG blocks is maximized
- Enriched regions which pass filter, but overlap with IgG block are also removed
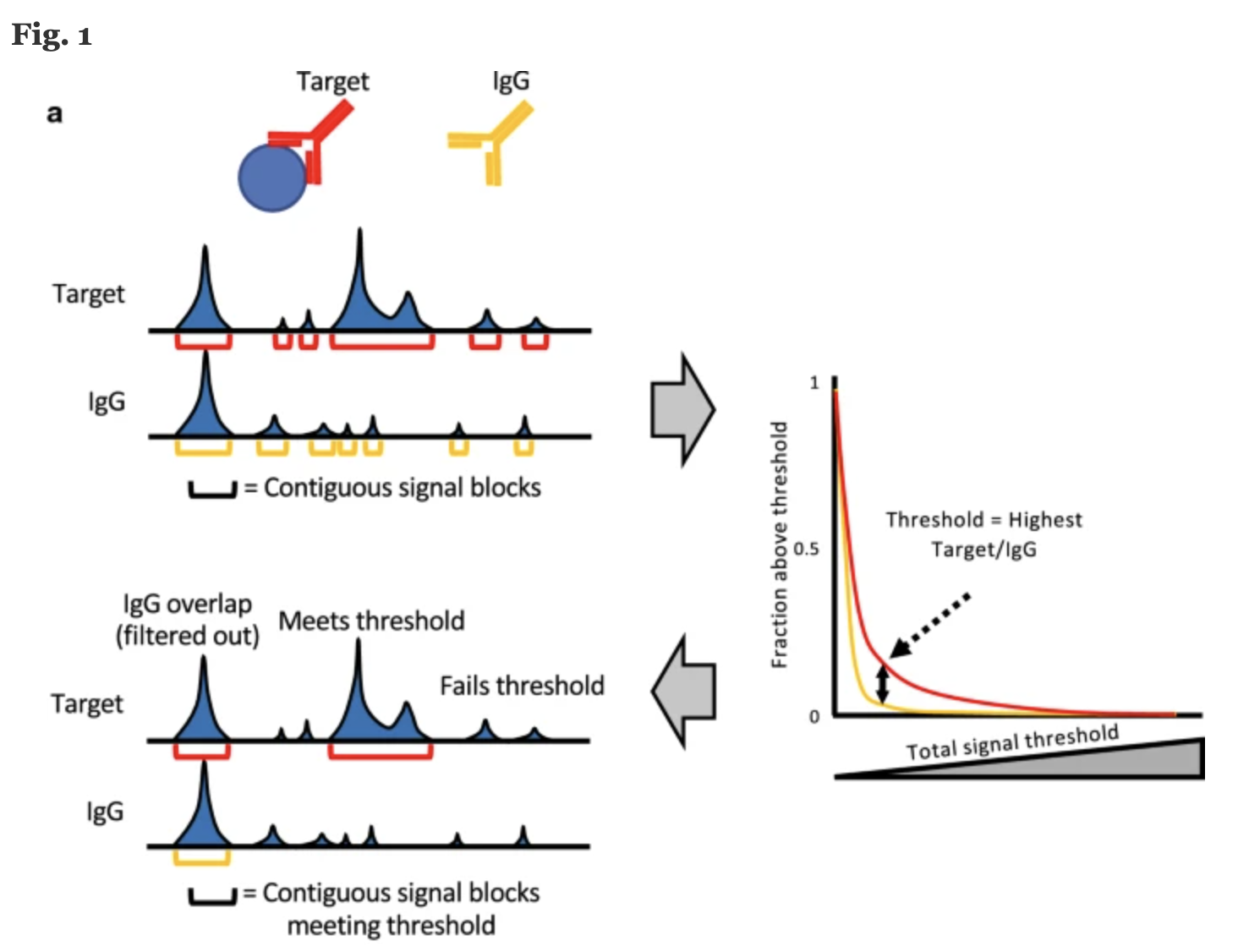
Image source: “Peak calling by Sparse Enrichment Analysis for CUT&RUN chromatin profiling”
ATAC-seq
The goal of ATAC-seq is to identify regions of accessible chromatin, and, by proxy, regulatory elements and sites of transcription factor binding. Calling peaks therefore represents the identification of regions of the genome that are enriched for aligned reads, similar to what we do for ChIP-seq. Currently, MACS2 is the default peak caller of the ENCODE ATAC-seq pipeline. There are several parameters that need to be changed compared to the ChIP-seq analysis workflow, and we describe them in detail towards the end of this lesson. Specifically, we need to account for the differences which include:
- Lack of an input sample (negative control)
- Lack of biomodal read distribution (i.e. no need to shift reads).
NOTE: There are additional ChIP-seq tools that have functionality to accomodate ATAC-seq data (i.e. Genrich, or there are caller that are exclusively designed for ATAC-seq(i.e. HMMRATAC).
MACS2
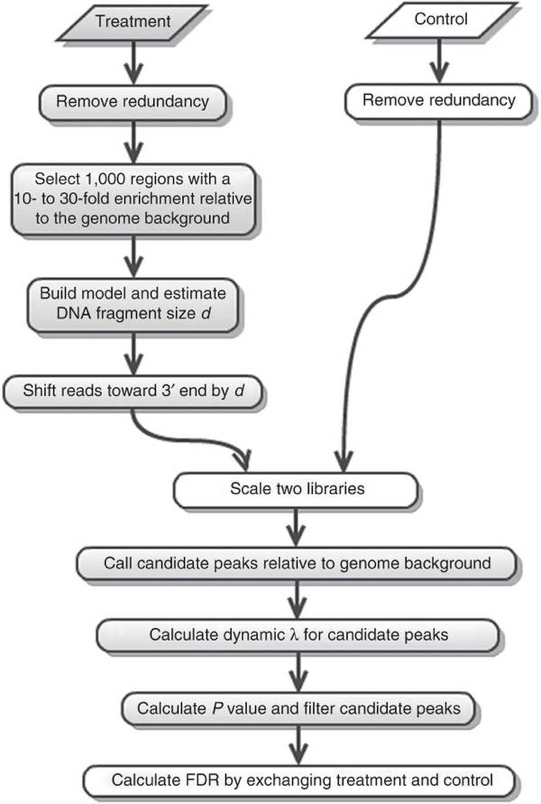
The MACS algorithm captures the influence of genome complexity to evaluate the significance of enriched ChIP regions. Although it was developed for the detection of transcription factor binding sites (narrow peaks), it is also suited for larger regions (broad peaks).
We will be using MACS2 in this workshop. The underlying algorithm for peak calling remains the same as the original MACS, but it comes with some enhancements in functionality. The MACS/MACS2 workflow is depicted below. In this lesson, we will describe the steps in more detail.
NOTE: You will notice that the link above points to MACS3, the newest version of this software. For this workshop we are limited to what is available as a module on O2, but if you have access to the latest version - we do recommend using it. The base algorithm does not change between versions, rather small tweaks have been made towards speed/memory optimization and code cleanup. There are also additional features added. For more details, please refer to the GitHub page.
Removing redundancy
MACS provides different options for dealing with duplicate tags at the exact same location, that is tags with the same coordination and the same strand. The default is to keep a single read at each location. The auto option, which is very commonly used, tells MACS to calculate the maximum tags at the exact same location based on binomal distribution using 1e-5 as the pvalue cutoff. An alternative is to set the all option, which keeps every tag. If an integer is specified, then at most that many tags will be kept at the same location. This redundancy is consistently applied for both the ChIP and input samples.
We do not need to worry about this option, since we filtered out the duplicates during the post-alignment filtering step.
The bimodal nature of ChIP-seq data
Below, we have illustrated the protein of interest and the fragments of DNA (green) which have been obtained from the immunoprecipitation.

As these fragments are typically sequenced from the 5’ end, the reads we obtain will not give us the fragment pileup shown in the image above. Rather, we get a read pileup on either side of the protein (on the positive and negative strand).

After aligining reads to the genome, the read density around a true binding site should show a bimodal enrichment pattern (or paired peaks).
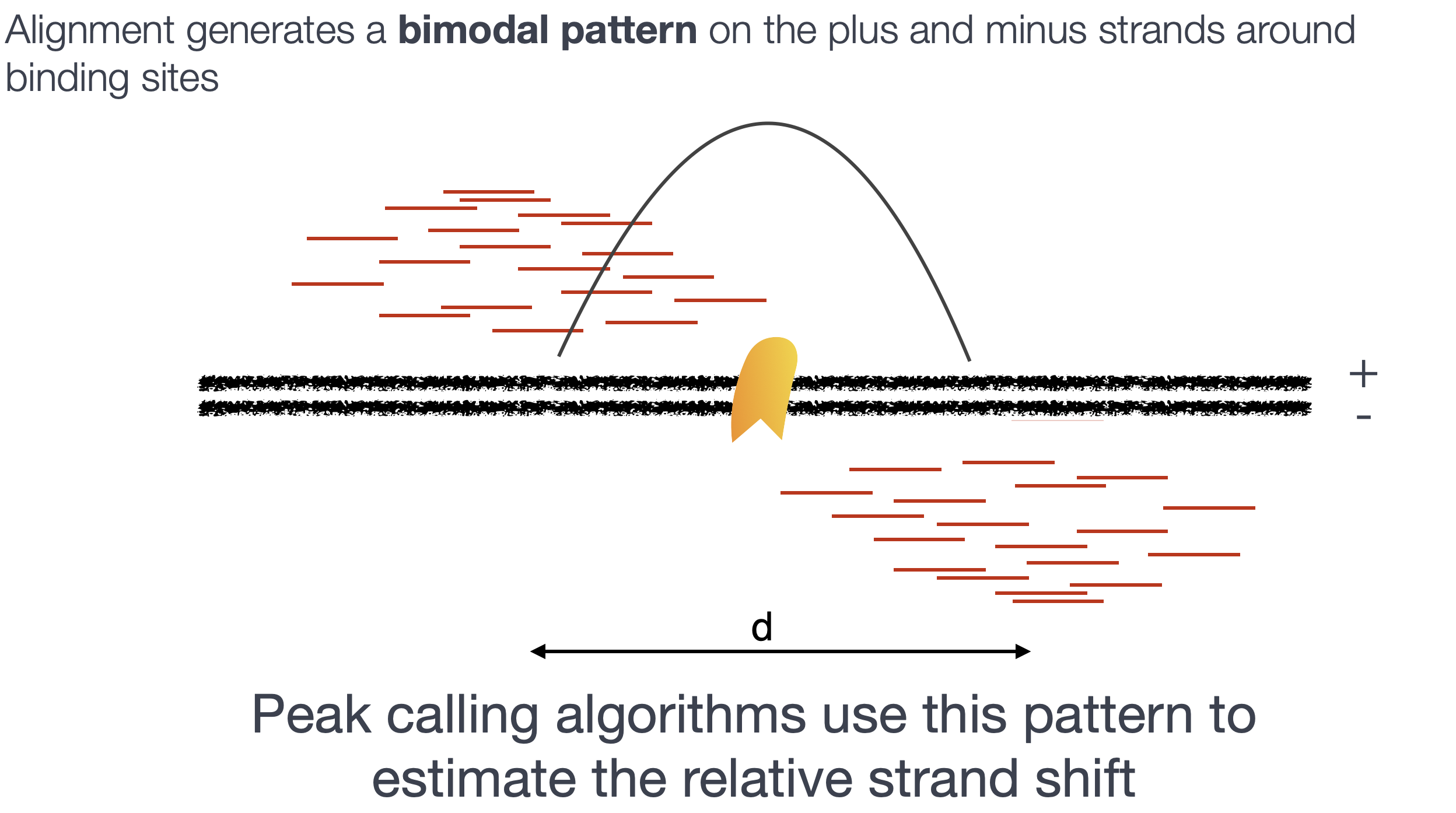
Modeling the shift size
MACS takes advantage of this bimodal pattern to empirically model the shifting size, thus better locating the precise binding sites.
To identify the shift size:
- MACS scans the whole sample searching for all highly significant enriched regions. This is done only using the ChIP sample!
- These regions are identified by MACS sliding across the genome using a 600bp window to find regions with tags more than 50-fold enriched relative to a random tag genome distribution.
Note 1: Both the window size and the fold enrichment values described above are the default values. Although there are parameters that allow you to modify these (i.e
bwandmfold), tweaking it is not recommended.Note 2: The default fold enrichment for MACS2 is greater than the value described in the workflow for MACSv1 above.
- MACS randomly samples 1,000 of these high-quality peaks identified in #1.
- For these 1,000 peaks, MACS separates their positive and negative strand tags and aligns them by the midpoint between their centers. The distance between the modes of the two peaks in the alignment is defined as ‘d’ and represents the estimated fragment length.
- MACS shifts all reads in the sample by d/2 toward the 3’ ends to the most likely protein-DNA interaction sites
Scaling libraries
For experiments in which sequence depth differs between input and treatment samples, MACS linearly scales the total control tag count to be the same as the total ChIP tag count. The default behaviour is for the larger sample to be scaled down.
Effective genome length
To calculate λbg (a parameter discussed below), MACS requires the effective genome size or the size of the genome that is mappable. Mappability is related to the uniqueness of the k-mers at a particular position the genome. Low-complexity and repetitive regions have low uniqueness, which means low mappability. Therefore we need to provide the effective genome length to correct for the loss of true signals in low-mappable regions.
How do I obtain the effective genome length?
The MACS software has some pre-computed values for commonly used organisms (human, mouse, worm and fly). If you wanted you could compute a more accurate values based on your organism and build. The deepTools docs has additional pre-computed values for more recent builds but also has some good materials on how to go about computing it.
Peak detection
After MACS shifts every tag by d/2, it then slides across the genome using a window size of 2d to find candidate peaks. The tag distribution along the genome can be modeled by a Poisson distribution. The Poisson is a one parameter model, where the parameter λ is the expected number of reads in that window. It is computed using only the input control sample.
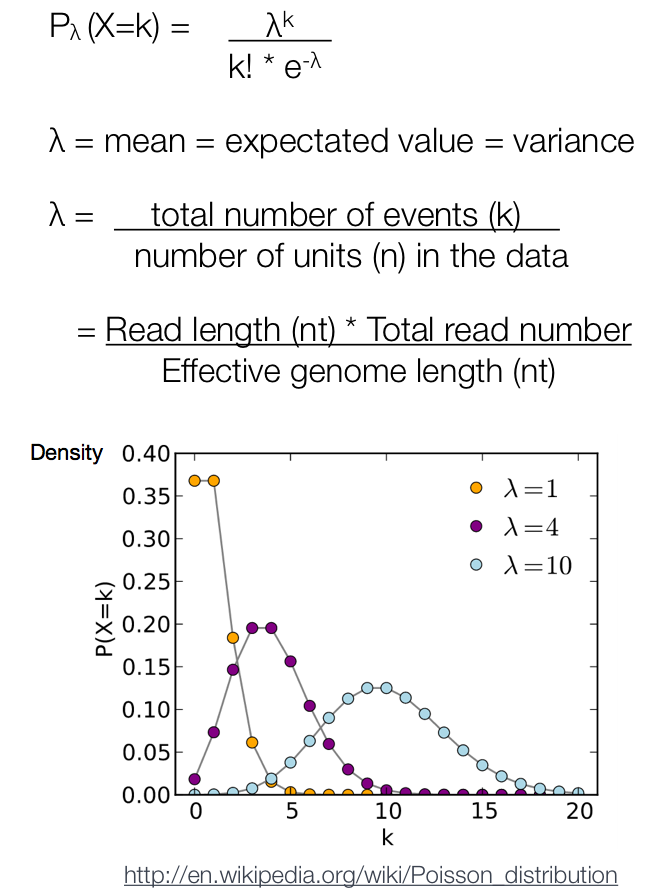
MACS computes a λlocal defined for each candidate peak. The λlocal parameter is deduced by computing a λ value for different window sizes (as shown below). From these values, the maximum value is retained to represent λlocal.

λlocal = MAX(λ300bp, λ1kb, λ5kb, λ10kb, λbg).
λbg represents the background λ estimated using the whole mappable genome (i.e. the largest window size)
In this way, lambda captures the influence of local biases, and is robust against occasional low tag counts at small local regions. Possible sources for these biases include local chromatin structure, DNA amplification and sequencing bias, and genome copy number variation.
Next, a Poisson distribution p-value is computed based on λ. A region is considered to have a significant tag enrichment if the p-value < 1e-5. Any overlapping enriched peaks are merged into a single peak.
Estimation of false discovery rate
Each peak is considered an independent test. Therefore, when we encounter thousands of significant peaks detected in a sample, we have a multiple testing problem. In MACSv1.4, the FDR was determined empirically by exchanging the ChIP and control samples. However, in MACS2, p-values are now corrected for multiple comparison using the Benjamini-Hochberg correction.
Other peak callers
There are many other tools out there that are capable of handling both types of profiles (e.g. narrow, broad); each having specific sub-commands and/or modes to do so. As such, it is good to have some idea about what type of binding profile you are expecting when choosing your peak caller to run.
Some other commonly referenced callers include:
- HOMER: a suite of tools for peak calling and motif discovery.
- SPP: an R package, that is implemented in the ENCODE processing pipeline. Best for narrow peak calling.
- Uses a sliding window to calculate scores based on fragment counts from up- and downstream flanking windows.
- epic2: Ideal for broad peak calling (a re-implementation of an older tool called SICER)
- haystack bio: Epigenetic Variability and Motif Analysis Pipeline
Running MACS2
To run MACS2, we will first load the macs2 module along with any dependencies:
$ module load gcc/6.2.0 python/2.7.12 macs2/2.1.1.20160309
We will also need to create a directory for the output generated from MACS2:
# Create macs2 directory in results
$ mkdir -p ~/chipseq_workshop/results/macs2
Now change directories to the results folder:
$ cd ~/chipseq_workshop/results/
Since we only created a filtered BAM file for a single sample, we will use the BAM files we have generated for you. Rather than copying them over, we will have you point to them within your peak calling command.
MACS2 parameters
There are seven major functions available in MACS2 serving as sub-commands. We will only cover callpeak in this lesson, but you can use macs2 COMMAND -h to find out more, if you are interested.
callpeak is the main function in MACS2 and can be invoked by typing macs2 callpeak. If you type this command without parameters, you will see a full description of commandline options. Here is a shorter list of the commonly used ones:
Input file options
-t: The ChIP data file (this is the only REQUIRED parameter for MACS)-c: The control or mock data file-f: format of input file; Default is “AUTO”, which will allow MACS to decide the format automatically.-g: mappable genome size, which is defined as the genome size that can be sequenced (1.0e+9 or 1000000000, are both accepted formats). Some precompiled values are provided (i.e. ‘hs’ for human (2.7e9), ‘mm’ for mouse (1.87e9), ‘ce’ for C. elegans (9e7) and ‘dm’ for fruitfly (1.2e8))
NOTE: While MACS can be used to call peaks without an input control, we advise against this. The control sample increases specificity of the peak calls, and without it you will find many false positive peaks identified.
Output arguments
--outdir: MACS2 will save all output files into speficied folder for this option-n: The prefix string for output files-B/--bdg: store the fragment pileup, control lambda, -log10pvalue and -log10qvalue scores in bedGraph files
Shifting model arguments
--nomodel: Whether or not to build the shifting model. Set to True for ATAC-seq peak-calling.--bw: The bandwidth, which is used to scan the genome ONLY for model building. Tweaking this is not recommended.--mfold: upper and lower limit for model building (defaults to 5 and 50). Tweaking this is not recommended.
Peak calling arguments
-q: q-value (minimum false discovery rate) cutoff for peak detection. By default this is set to 0.05 and the p-value is not considered.-p: p-value cutoff. This is mutually exclusive with-q. Use in place of q-value for a more lenient threshold (see note below). If p-value cutoff is set, qvalue will not be calculated and reported as -1 in the final .xls file--nolambda: do not consider the local bias/lambda at peak candidate regions--broad: broad peak calling
NOTE: Relaxing the q-value does not behave as expected in this case, since it is partially tied to peak widths. Ideally, if you relaxed the thresholds, you would simply get more peaks. But with MACS2, relaxing thresholds also results in wider peaks.
Now that we have a feel for the different ways we can modify our command, let’s set up the command for each of our wildtype replicates:
macs2 callpeak -t /n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/wt_sample1_chip_final.bam \
-c /n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/wt_sample1_input_final.bam \
-f BAM -g mm \
-n wt_sample1 \
--outdir macs2 2> macs2/wt_sample1_macs2.log
$ macs2 callpeak -t /n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/wt_sample2_chip_final.bam \
-c /n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/wt_sample2_input_final.bam \
-f BAM -g mm \
-n wt_sample2 \
--outdir macs2 2> macs2/wt_sample2_macs2.log
The tool is quite verbose, and normally you would see lines of text being printed to the terminal, describing each step that is being carried out. We have captured that information into a log file using 2> to re-direct the stadard error to file. You can use less to look at the log file and see what information is being reported.
Move the log files to the log directory we had created during our project setup:
$ mv macs2/*.log ../logs/
As a general peak-caller, MACS2 can be applied to any DNA enrichment assays if the question to be asked is simply: “Where we can find significant reads coverage than the random background?” Below, we comment on changes required for peak calling on CUT&RUN and ATAC-seq data.
How do the parameters change for CUT&RUN?
There is very little required change for peak calling on CUT&RUN-seq data. The only notable difference is the CUT&RUN sequencing data will typically be paired-end. To account for this, you can add the format parameter.
-f BAMPE: Paired-end analysis mode in MACS2. In this mode, MACS2 interprets the full extent of the sequenced DNA fragments correctly, and discards alignments that are not properly paired.
How do the parameters change for ATAC-seq
To identify acccessible regions in the genome we need to call peaks on the nucleosome-free BAM file obtained post-filtering. Currently, MACS2 is the default peak caller of the ENCODE ATAC-seq pipeline, and so below we provide the recommended parameter changes if using ATAC-seq data as input.
-f BAMPE: Paired-end analysis mode in MACS2.--nomodel: Bypass building the shifting model. The read pileup does not represent a bimodal pattern, as there is no specific protein-DNA interaction that we are assaying. Open regions will be unimodal in nature, not requiring any shifting of reads.--keep-dup all: Keep all reads since we have already filtered duplicates from our BAM files.--nolambda: MACS2 will use the background lambda as local lambda (since we have no input control samples for ATAC-seq)
MACS2 Output files
Change directories into macs2, and list the output files that we have generated.
$ cd macs2/
$ ls -lh
There should be 4 files output to the results directory for each sample (2 replicates), so a total of 8 files:
_peaks.narrowPeak: BED6+4 format file which contains the peak locations together with peak summit, pvalue and qvalue_peaks.xls: a tabular file which contains information about called peaks. Additional information includes pileup and fold enrichment (the ratio between the ChIP-seq tag count and λlocal)_summits.bed: The location in the peak with the highest fragment pileup. These are the predicted precise binding location and recommended to use for motif finding._model.R: an R script which you can use to produce a PDF image about the model based on your data and cross-correlation plot
Let’s first obtain a summary of how many peaks were called in each sample. We can do this by counting the lines in the .narrowPeak files:
$ wc -l *.narrowPeak
Exercise:
- Using the BAM files listed below, use MACS2 to call peaks on the KO samples.
# KO ChIP BAM files
/n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/ko_sample1_chip_final.bam
/n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/ko_sample2_chip_final.bam
# KO input BAM files
/n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/ko_sample1_input_final.bam
/n/groups/hbctraining/harwell-datasets/workshop_material/results/bowtie2/ko_sample2_input_final.bam
- How many peaks do you get for each sample? How does this compare with the WT?
In the next lesson, we will delve deeper into the output files and gain an understanding of the different file formats.
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.