Approximate time: 120 minutes
Learning Objectives:
- Determine how functions are attributed to genes using Gene Ontology terms
- Understand the theory of how functional enrichment tools yield statistically enriched functions or interactions
- Discuss functional analysis using over-representation analysis, functional class scoring, and pathway topology methods
- Explore functional analysis tools
Functional analysis
The output of RNA-seq differential expression analysis is a list of significant differentially expressed genes (DEGs). To gain greater biological insight on the differentially expressed genes there are various analyses that can be done:
- determine whether there is enrichment of known biological functions, interactions, or pathways
- identify genes’ involvement in novel pathways or networks by grouping genes together based on similar trends
- use global changes in gene expression by visualizing all genes being significantly up- or down-regulated in the context of external interaction data
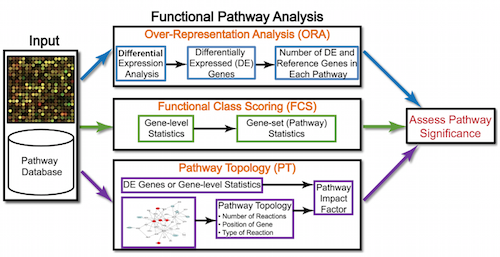
Generally for any differential expression analysis, it is useful to interpret the resulting gene lists using freely available web- and R-based tools. While tools for functional analysis span a wide variety of techniques, they can loosely be categorized into three main types: over-representation analysis, functional class scoring, and pathway topology [1].
The goal of functional analysis is provide biological insight, so it’s necessary to analyze our results in the context of our experimental hypothesis: FMRP and MOV10 associate and regulate the translation of a subset of RNAs. Therefore, based on the authors’ hypothesis, we may expect the enrichment of processes/pathways related to translation, splicing, and the regulation of mRNAs, which we would need to validate experimentally.
Note that all tools described below are great tools to validate experimental results and to make hypotheses. These tools suggest genes/pathways that may be involved with your condition of interest; however, you should NOT use these tools to make conclusions about the pathways involved in your experimental process. You will need to perform experimental validation of any suggested pathways.
Over-representation analysis
There are a plethora of functional enrichment tools that perform some type of “over-representation” analysis by querying databases containing information about gene function and interactions.
These databases typically categorize genes into groups (gene sets) based on shared function, or involvement in a pathway, or presence in a specific cellular location, or other categorizations, e.g. functional pathways, etc. Essentially, known genes are binned into categories that have been consistently named (controlled vocabulary) based on how the gene has been annotated functionally. These categories are independent of any organism, however each organism has distinct categorizations available.
To determine whether any categories are over-represented, you can determine the probability of having the observed proportion of genes associated with a specific category in your gene list based on the proportion of genes associated with the same category in the background set (gene categorizations for the appropriate organism).

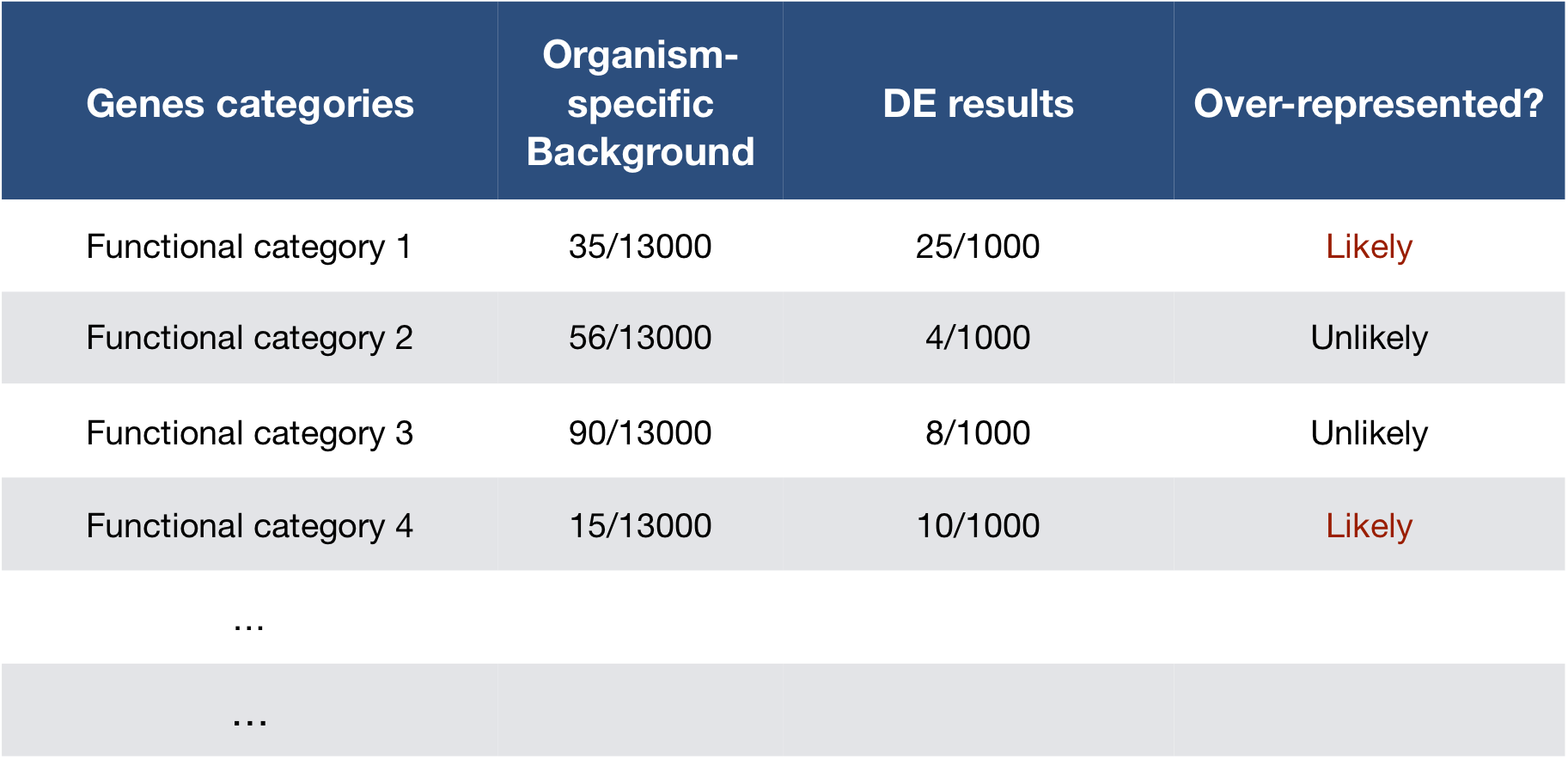
The statistical test that will determine whether something is actually over-represented is the Hypergeometric test.
Hypergeometric testing
Using the example of the first functional category above, hypergeometric distribution is a probability distribution that describes the probability of 25 genes (k) being associated with “Functional category 1”, for all genes in our gene list (n=1000), from a population of all of the genes in entire genome (N=13,000) which contains 35 genes (K) associated with “Functional category 1” [4].
The calculation of probability of k successes follows the formula:
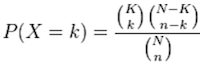
This test will result in an adjusted p-value (after multiple test correction) for each category tested.
Gene Ontology project
One of the most widely-used categorizations is the Gene Ontology (GO) established by the Gene Ontology project.
“The Gene Ontology project is a collaborative effort to address the need for consistent descriptions of gene products across databases” [2]. The Gene Ontology Consortium maintains the GO terms, and these GO terms are incorporated into gene annotations in many of the popular repositories for animal, plant, and microbial genomes.
Tools that investigate enrichment of biological functions or interactions often use the Gene Ontology (GO) categorizations, i.e. the GO terms to determine whether any have significantly modified representation in a given list of genes. Therefore, to best use and interpret the results from these functional analysis tools, it is helpful to have a good understanding of the GO terms themselves and their organization.
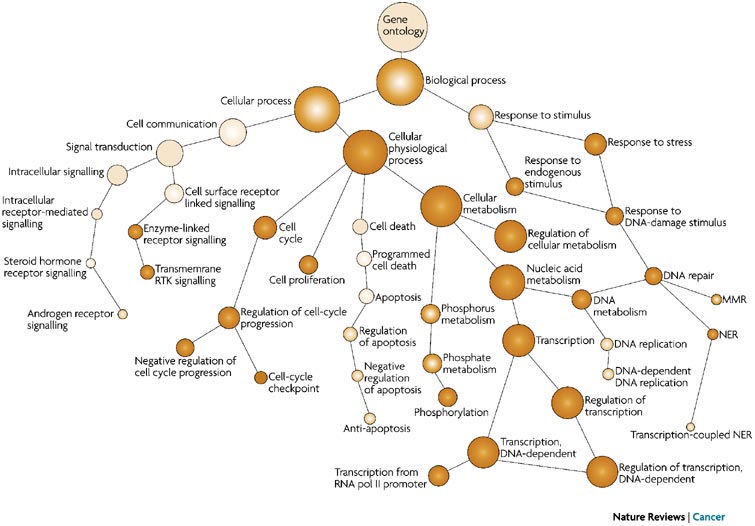
GO Ontologies
To describe the roles of genes and gene products, GO terms are organized into three independent controlled vocabularies (ontologies) in a species-independent manner:
- Biological process: refers to the biological role involving the gene or gene product, and could include “transcription”, “signal transduction”, and “apoptosis”. A biological process generally involves a chemical or physical change of the starting material or input.
- Molecular function: represents the biochemical activity of the gene product, such activities could include “ligand”, “GTPase”, and “transporter”.
- Cellular component: refers to the location in the cell of the gene product. Cellular components could include “nucleus”, “lysosome”, and “plasma membrane”.
Each GO term has a term name (e.g. DNA repair) and a unique term accession number (GO:0005125), and a single gene product can be associated with many GO terms, since a single gene product “may function in several processes, contain domains that carry out diverse molecular functions, and participate in multiple alternative interactions with other proteins, organelles or locations in the cell” [3].
GO term hierarchy
Some gene products are well-researched, with vast quantities of data available regarding their biological processes and functions. However, other gene products have very little data available about their roles in the cell.
For example, the protein, “p53”, would contain a wealth of information on it’s roles in the cell, whereas another protein might only be known as a “membrane-bound protein” with no other information available.
The GO ontologies were developed to describe and query biological knowledge with differing levels of information available. To do this, GO ontologies are loosely hierarchical, ranging from general, ‘parent’, terms to more specific, ‘child’ terms. The GO ontologies are “loosely” hierarchical since ‘child’ terms can have multiple ‘parent’ terms.
Some genes with less information may only be associated with general ‘parent’ terms or no terms at all, while other genes with a lot of information be associated with many terms.
Tips for working with GO terms
clusterProfiler
We will be using clusterProfiler to perform over-representation analysis on GO terms associated with our list of significant genes. The tool takes as input a significant gene list and a background gene list and performs statistical enrichment analysis using hypergeometric testing. The basic arguments allow the user to select the appropriate organism and GO ontology (BP, CC, MF) to test.
Load the following libraries:
# Load libraries
library(DOSE)
library(pathview)
library(clusterProfiler)
Download the annotation file
Download the annotations to your data folder by right-clicking here and selecting “Save link as…“_
Run the following code to read the annotation file in:
annotations_ahb <- read.csv("data/annotations_ahb.csv")
To run clusterProfiler GO over-representation analysis, we will change our gene names into Ensembl IDs, since the tool works a bit easier with the Ensembl IDs. Also, for the different steps in the functional analysis, we require Ensembl and Entrez IDs. We will use new gene annotations to merge with our differential expression results.
## Merge the AnnotationHub dataframe with the results
res_ids <- inner_join(res_tableOE_tb, annotations_ahb, by=c("gene"="gene_name"))
Create Gene lists
To perform the over-representation analysis, we need a list of background genes and a list of significant genes. For our background dataset we will use all genes tested for differential expression (all genes in our results table). For our significant gene list we will use genes with p-adjusted values less than 0.05 (we could include a fold change threshold too if we have many DE genes).
## Create background dataset for hypergeometric testing using all genes tested for significance in the results
allOE_genes <- as.character(res_ids$gene_id)
## Extract significant results
sigOE <- dplyr::filter(res_ids, padj < 0.05)
sigOE_genes <- as.character(sigOE$gene_id)
Using ClusterProfiler
Now we can perform the GO enrichment analysis and save the results:
## Run GO enrichment analysis
ego <- enrichGO(gene = sigOE_genes,
universe = allOE_genes,
keyType = "ENSEMBL",
OrgDb = org.Hs.eg.db,
ont = "BP",
pAdjustMethod = "BH",
qvalueCutoff = 0.05,
readable = TRUE)
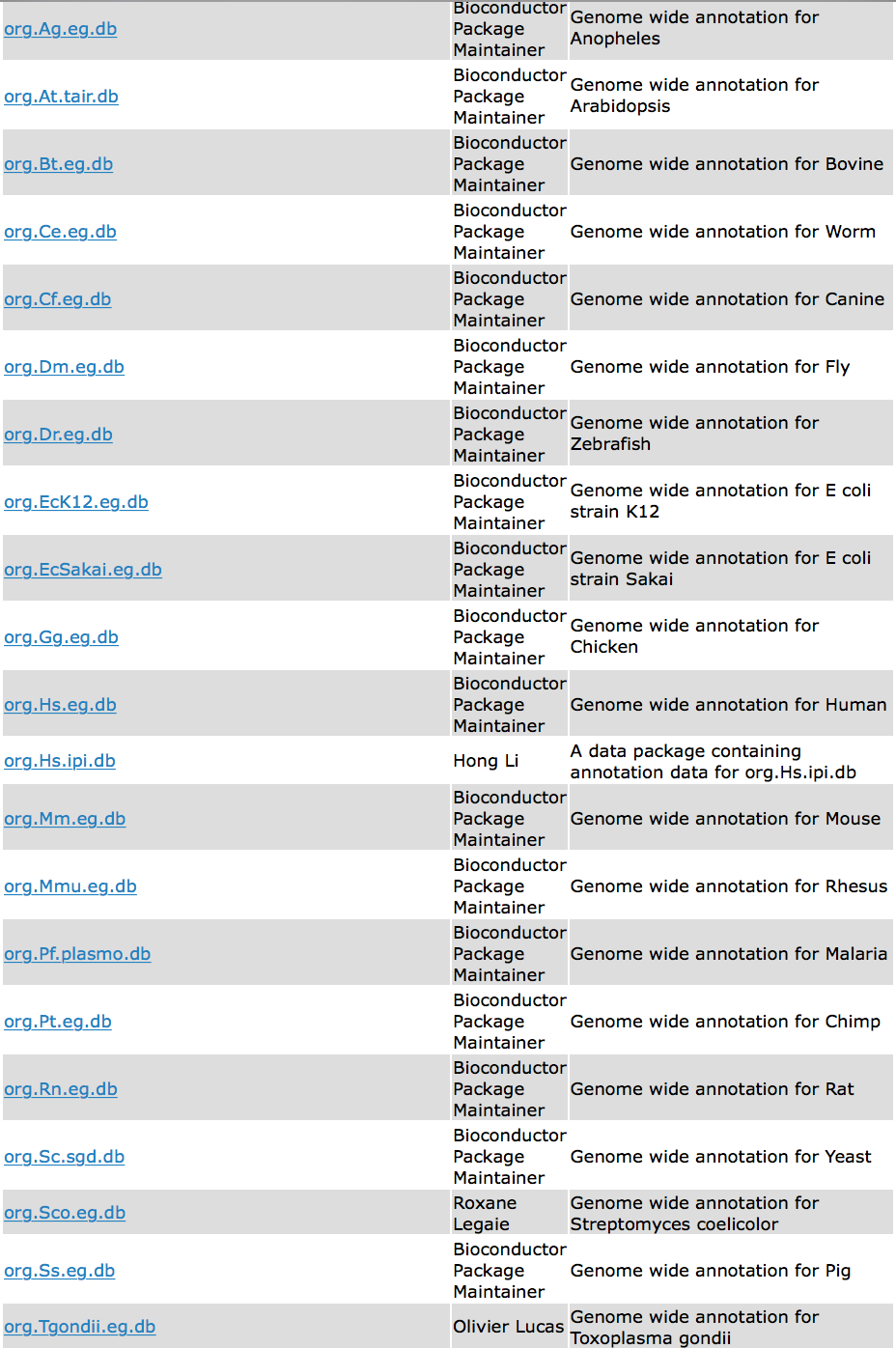
NOTE: The different organisms with annotation databases available to use with for the
OrgDbargument can be found here.Also, the
keyTypeargument may be coded askeytypein different versions of clusterProfiler.Finally, the
ontargument can accept either “BP” (Biological Process), “MF” (Molecular Function), and “CC” (Cellular Component) subontologies, or “ALL” for all three.
{kind=link}
## Output results from GO analysis to a table
cluster_summary <- data.frame(ego)
write.csv(cluster_summary, "results/clusterProfiler_Mov10oe.csv")
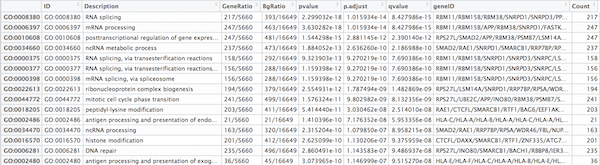
NOTE: Instead of saving just the results summary from the
egoobject, it might also be beneficial to save the object itself. Thesave()function enables you to save it as a.rdafile, e.g.save(ego, file="results/ego.rda"). The complementary function tosave()is the functionload(), e.g.ego <- load(file="results/ego.rda").This is a useful set of functions to know, since it enables one to preserve analyses at specific stages and reload them when needed. More information about these functions can be found here & here.
Visualizing clusterProfiler results
clusterProfiler has a variety of options for viewing the over-represented GO terms. We will explore the dotplot, enrichment plot, and the category netplot.
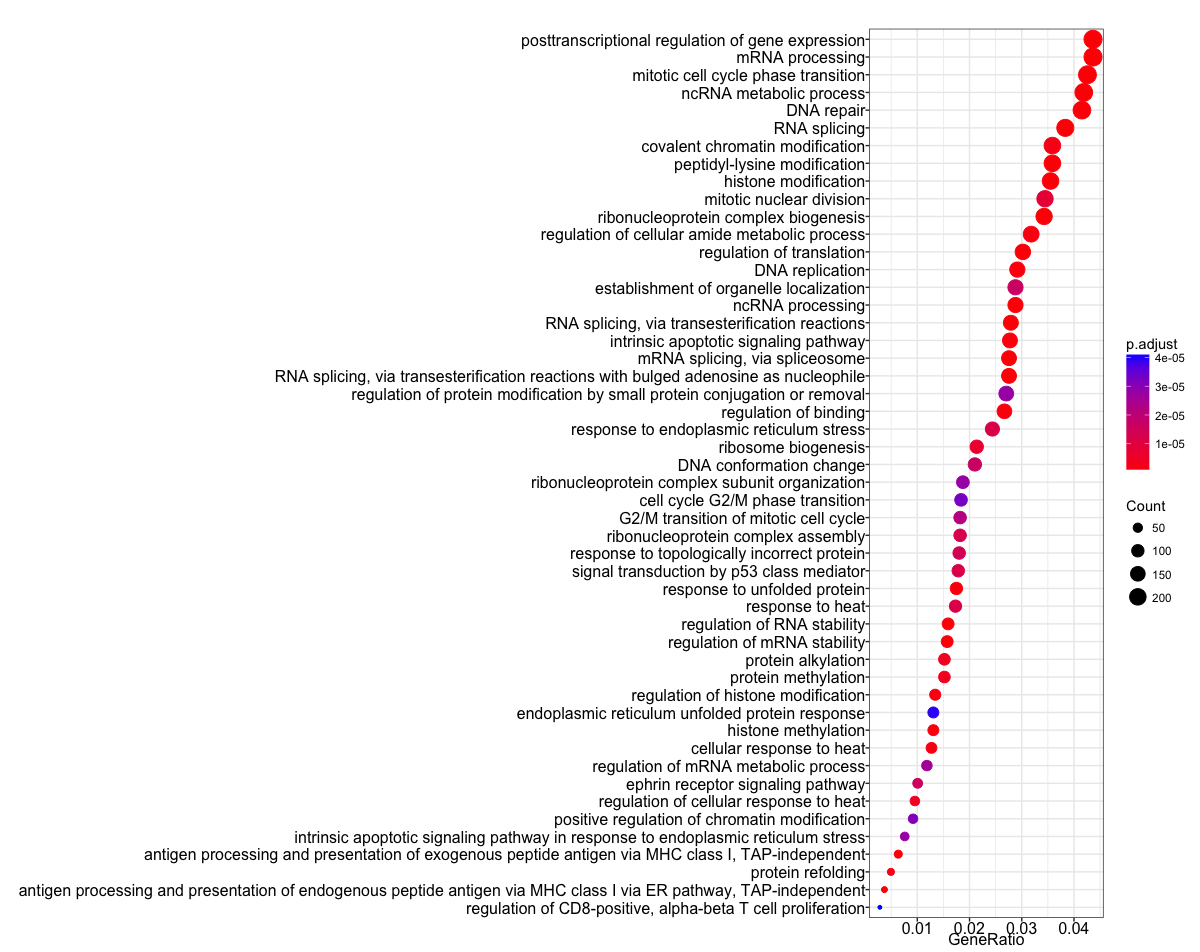
The dotplot shows the number of genes associated with the first 50 terms (size) and the p-adjusted values for these terms (color). This plot displays the top 50 GO terms by gene ratio (# genes related to GO term / total number of sig genes), not p-adjusted value.
## Dotplot
dotplot(ego, showCategory=50)
To save the figure, click on the Export button in the RStudio Plots tab and Save as PDF.... In the pop-up window, change:
Orientation:toLandscapePDF sizeto8 x 14to give a figure of appropriate size for the text labels
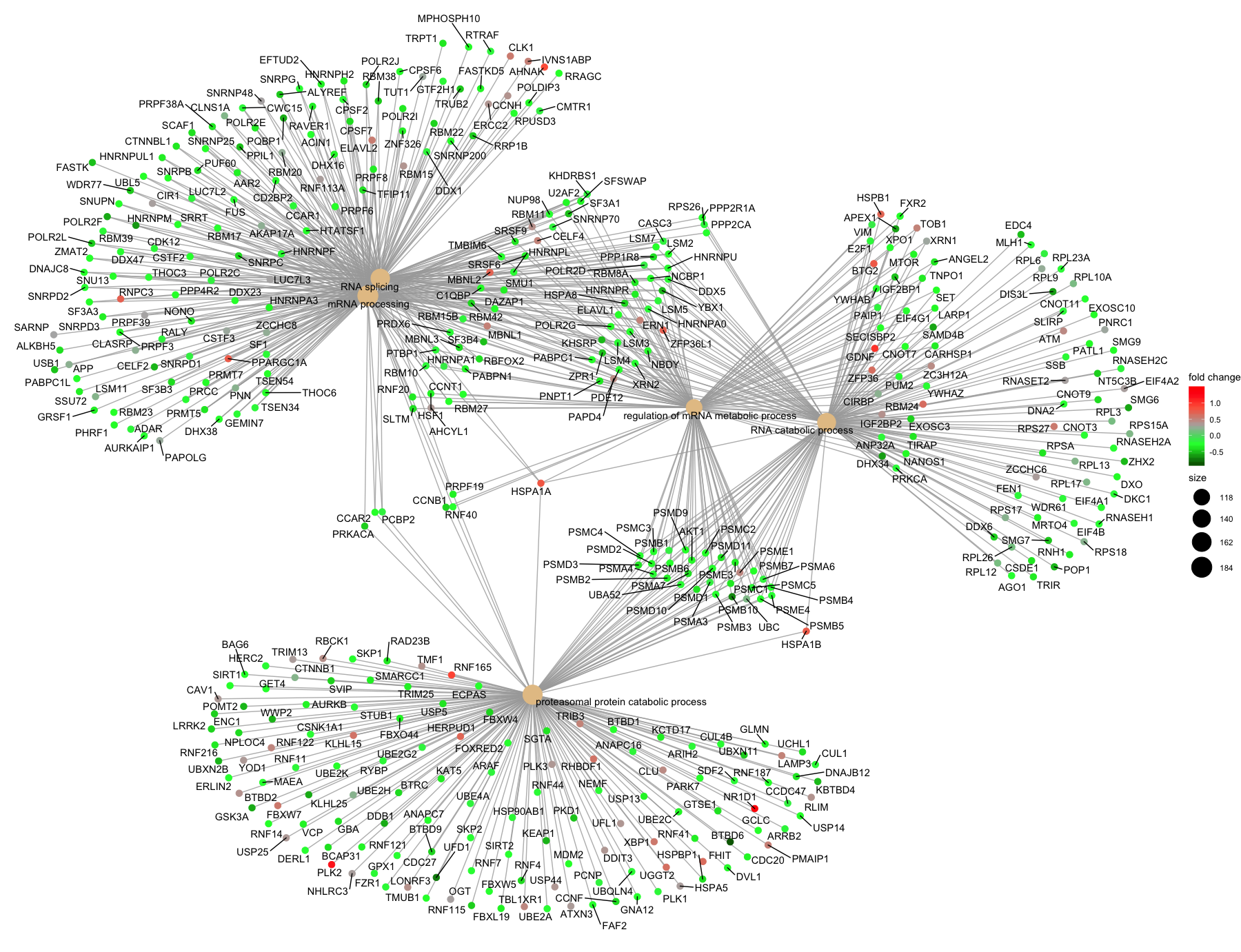
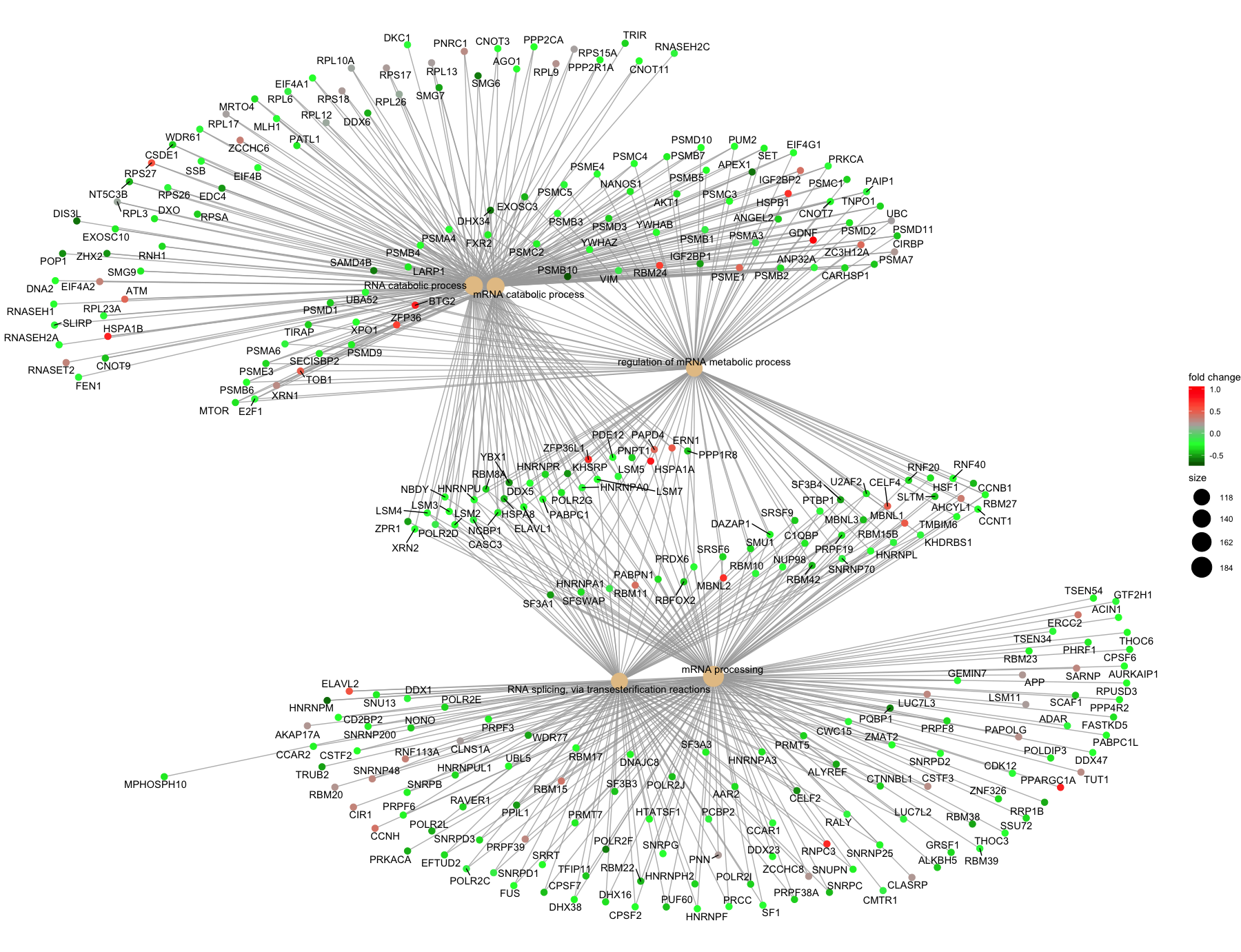
Next, the category netplot shows the relationships between the genes associated with the top five most significant GO terms and the fold changes of the significant genes associated with these terms (color). The size of the GO terms reflects the pvalues of the terms, with the more significant terms being larger. This plot is particularly useful for hypothesis generation in identifying genes that may be important to several of the most affected processes.
## To color genes by log2 fold changes, we need to extract the log2 fold changes from our results table creating a named vector
OE_foldchanges <- sigOE$log2FoldChange
names(OE_foldchanges) <- sigOE$gene
## Cnetplot details the genes associated with one or more terms - by default gives the top 5 significant terms (by padj)
cnetplot(ego,
categorySize="pvalue",
showCategory = 5,
foldChange=OE_foldchanges,
vertex.label.font=6)
## If some of the high fold changes are getting drowned out due to a large range, you could set a maximum fold change value
OE_foldchanges <- ifelse(OE_foldchanges > 2, 2, OE_foldchanges)
OE_foldchanges <- ifelse(OE_foldchanges < -2, -2, OE_foldchanges)
cnetplot(ego,
categorySize="pvalue",
showCategory = 5,
foldChange=OE_foldchanges,
vertex.label.font=6)
NOTE: You might get an error saying
Error in loadNamespace(name) : there is no package called 'ggnewscale', in that case install it using `install.packages(“ggnewscale”) and try plotting the Cnetplot again.
Again, to save the figure, click on the Export button in the RStudio Plots tab and Save as PDF.... Change the PDF size to 12 x 14 to give a figure of appropriate size for the text labels.
If you are interested in significant processes that are not among the top five, you can subset your ego dataset to only display these processes:
## Subsetting the ego results without overwriting original `ego` variable
ego2 <- ego
ego2@result <- ego@result[c(1,3,4,8,9),]
## Plotting terms of interest
cnetplot(ego2,
categorySize="pvalue",
foldChange=OE_foldchanges,
showCategory = 5,
vertex.label.font=6)
Other methods for functional analysis
Over-representation analysis is only a single type of functional analysis method that is available for teasing apart the biological processes important to your condition of interest. Other types of analyses can be equally important or informative, including functional class scoring and pathway topology methods.
Functional class scoring tools
Functional class scoring (FCS) tools, such as GSEA, most often use the gene-level statistics or log2 fold changes for all genes from the differential expression results, then look to see whether gene sets for particular biological pathways are enriched among the large positive or negative fold changes.
The hypothesis of FCS methods is that although large changes in individual genes can have significant effects on pathways (and will be detected via ORA methods), weaker but coordinated changes in sets of functionally related genes (i.e., pathways) can also have significant effects. Thus, rather than setting an arbitrary threshold to identify ‘significant genes’, all genes are considered in the analysis. The gene-level statistics from the dataset are aggregated to generate a single pathway-level statistic and statistical significance of each pathway is reported. This type of analysis can be particularly helpful if the differential expression analysis only outputs a small list of significant DE genes.
Gene set enrichment analysis using clusterProfiler and Pathview
Using the log2 fold changes obtained from the differential expression analysis for every gene, gene set enrichment analysis and pathway analysis can be performed using clusterProfiler and Pathview tools.
For gene set or pathway analysis using clusterProfiler, coordinated differential expression over gene sets is tested instead of changes of individual genes. “Gene sets are pre-defined groups of genes, which are functionally related. Commonly used gene sets include those derived from KEGG pathways, Gene Ontology terms, MSigDB, Reactome, or gene groups that share some other functional annotations, etc. Consistent perturbations over such gene sets frequently suggest mechanistic changes” [1].
To perform GSEA analysis of KEGG gene sets, clusterProfiler requires the genes to be identified using Entrez IDs for all genes in our results dataset. We also need to remove the NA values and duplicates (due to gene ID conversion) prior to the analysis:
## Remove any NA values (reduces the data by quite a bit)
res_entrez <- dplyr::filter(res_ids, entrezid != "NA")
## Remove any Entrez duplicates
res_entrez <- res_entrez[which(duplicated(res_entrez$entrezid) == F), ]
Finally, extract and name the fold changes:
## Extract the foldchanges
foldchanges <- res_entrez$log2FoldChange
## Name each fold change with the corresponding Entrez ID
names(foldchanges) <- res_entrez$entrezid
Next we need to order the fold changes in decreasing order. To do this we’ll use the sort() function, which takes a vector as input. This is in contrast to Tidyverse’s arrange(), which requires a data frame.
## Sort fold changes in decreasing order
foldchanges <- sort(foldchanges, decreasing = TRUE)
head(foldchanges)
Perform the GSEA using KEGG gene sets:
## GSEA using gene sets from KEGG pathways
gseaKEGG <- gseKEGG(geneList = foldchanges, # ordered named vector of fold changes (Entrez IDs are the associated names)
organism = "hsa", # supported organisms listed below
nPerm = 1000, # default number permutations
minGSSize = 20, # minimum gene set size (# genes in set) - change to test more sets or recover sets with fewer # genes
pvalueCutoff = 0.05, # padj cutoff value
verbose = FALSE)
## Extract the GSEA results
gseaKEGG_results <- gseaKEGG@result
NOTE: The organisms with KEGG pathway information are listed here.
How many pathways are enriched? View the enriched pathways:
## Write GSEA results to file
View(gseaKEGG_results)
write.csv(gseaKEGG_results, "results/gseaOE_kegg.csv", quote=F)
NOTE: We will all get different results for the GSEA because the permutations performed use random reordering. If we would like to use the same permutations every time we run a function (i.e. we would like the same results every time we run the function), then we could use the
set.seed(123456)function prior to running. The input toset.seed()could be any number, but if you would want the same results, then you would need to use the same number as input.
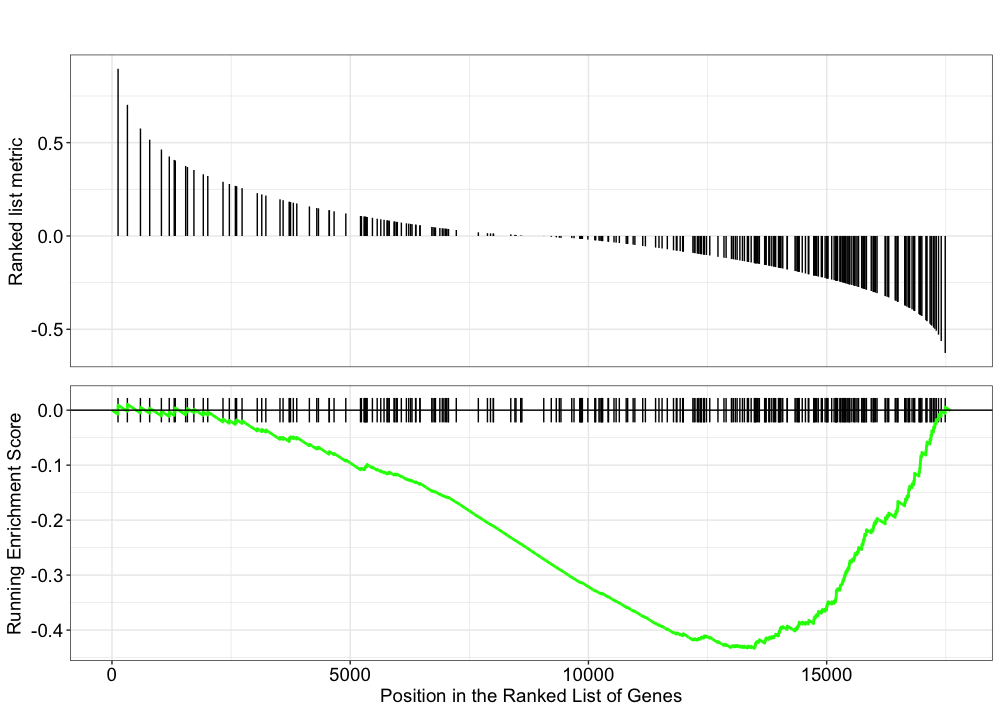
Explore the GSEA plot of enrichment of one of the pathways in the ranked list:
## Plot the GSEA plot for a single enriched pathway, `hsa03040`
gseaplot(gseaKEGG, geneSetID = 'hsa03040')
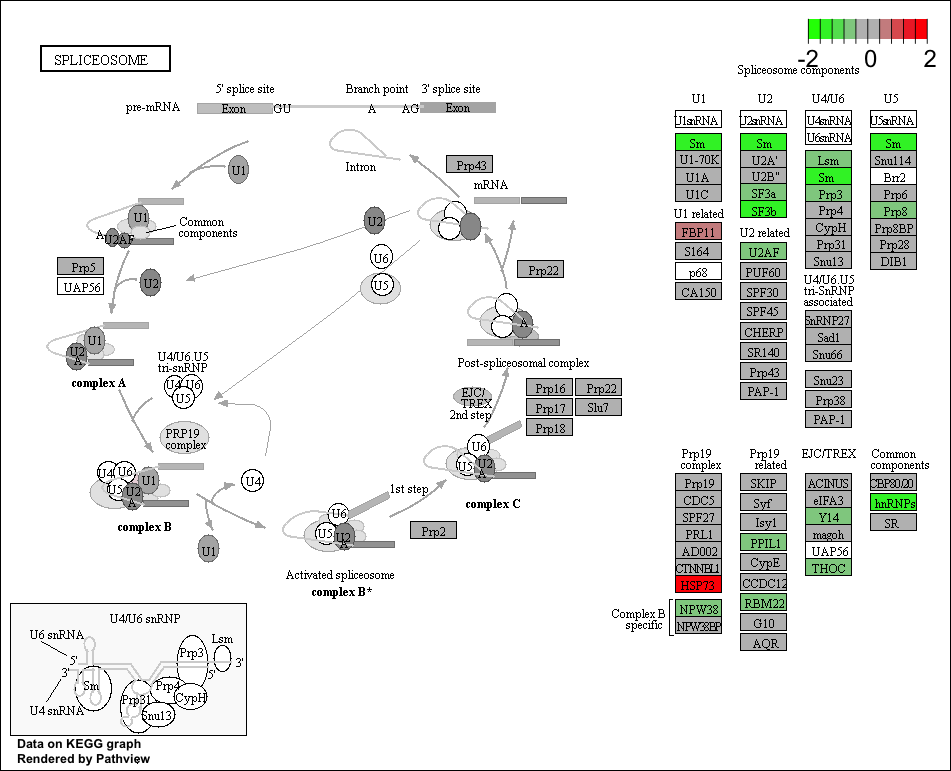
Use the Pathview R package to integrate the KEGG pathway data from clusterProfiler into pathway images:
detach("package:dplyr", unload=TRUE) # first unload dplyr to avoid conflicts
## Output images for a single significant KEGG pathway
pathview(gene.data = foldchanges,
pathway.id = "hsa03040",
species = "hsa",
limit = list(gene = 2, # value gives the max/min limit for foldchanges
cpd = 1))
NOTE: If the below error message occurs:
Error in detach("package:dplyr", unload = T) : invalid 'name' argument, that means the dplyr package is not currently loaded. Ignore the message and continue to run pathview command.
NOTE: Printing out Pathview images for all significant pathways can be easily performed as follows:
## Output images for all significant KEGG pathways get_kegg_plots <- function(x) { pathview(gene.data = foldchanges, pathway.id = gseaKEGG_results$ID[x], species = "hsa", limit = list(gene = 2, cpd = 1)) } purrr::map(1:length(gseaKEGG_results$ID), get_kegg_plots)
Instead of exploring enrichment of KEGG gene sets, we can also explore the enrichment of BP Gene Ontology terms using gene set enrichment analysis:
# GSEA using gene sets associated with BP Gene Ontology terms
gseaGO <- gseGO(geneList = foldchanges,
OrgDb = org.Hs.eg.db,
ont = 'BP',
nPerm = 1000,
minGSSize = 20,
pvalueCutoff = 0.05,
verbose = FALSE)
gseaGO_results <- gseaGO@result
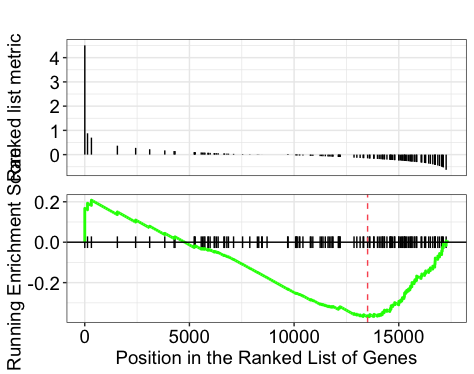
gseaplot(gseaGO, geneSetID = 'GO:0007423')
There are other gene sets available for GSEA analysis in clusterProfiler (Disease Ontology, Reactome pathways, etc.). In addition, it is possible to supply your own gene set GMT file, such as a GMT for MSigDB using special clusterProfiler functions as shown below:
BiocManager::install("GSEABase")
library(GSEABase)
# Load in GMT file of gene sets (we downloaded from the Broad Institute for MSigDB)
c2 <- read.gmt("/data/c2.cp.v6.0.entrez.gmt.txt")
msig <- GSEA(foldchanges, TERM2GENE=c2, verbose=FALSE)
msig_df <- data.frame(msig)
Pathway topology tools
The last main type of functional analysis technique is pathway topology analysis. Pathway topology analysis often takes into account gene interaction information along with the fold changes and adjusted p-values from differential expression analysis to identify dysregulated pathways. Depending on the tool, pathway topology tools explore how genes interact with each other (e.g. activation, inhibition, phosphorylation, ubiquitination, etc.) to determine the pathway-level statistics. Pathway topology-based methods utilize the number and type of interactions between gene product (our DE genes) and other gene products to infer gene function or pathway association.
For instance, the SPIA (Signaling Pathway Impact Analysis) tool can be used to integrate the lists of differentially expressed genes, their fold changes, and pathway topology to identify affected pathways. We have step-by-step materials for using SPIA available.
Other Tools
Co-expression clustering
Co-expression clustering is often used to identify genes of novel pathways or networks by grouping genes together based on similar trends in expression. These tools are useful in identifying genes in a pathway, when their participation in a pathway and/or the pathway itself is unknown. These tools cluster genes with similar expression patterns to create ‘modules’ of co-expressed genes which often reflect functionally similar groups of genes. These ‘modules’ can then be compared across conditions or in a time-course experiment to identify any biologically relevant pathway or network information.
You can visualize co-expression clustering using heatmaps, which should be viewed as suggestive only; serious classification of genes needs better methods.
The way the tools perform clustering is by taking the entire expression matrix and computing pair-wise co-expression values. A network is then generated from which we explore the topology to make inferences on gene co-regulation. The WGCNA package (in R) is one example of a more sophisticated method for co-expression clustering.
Resources for functional analysis
- g:Profiler - http://biit.cs.ut.ee/gprofiler/index.cgi
- DAVID - http://david.abcc.ncifcrf.gov/tools.jsp
- clusterProfiler - http://bioconductor.org/packages/release/bioc/html/clusterProfiler.html
- GeneMANIA - http://www.genemania.org/
- GenePattern - http://www.broadinstitute.org/cancer/software/genepattern/ (need to register)
- WebGestalt - http://bioinfo.vanderbilt.edu/webgestalt/ (need to register)
- AmiGO - http://amigo.geneontology.org/amigo
- ReviGO (visualizing GO analysis, input is GO terms) - http://revigo.irb.hr/
- WGCNA - https://horvath.genetics.ucla.edu/html/CoexpressionNetwork/Rpackages/WGCNA/
- GSEA - http://software.broadinstitute.org/gsea/index.jsp
- SPIA - https://www.bioconductor.org/packages/release/bioc/html/SPIA.html
- GAGE/Pathview - http://www.bioconductor.org/packages/release/bioc/html/gage.html
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.