Learning Objectives
- Describe the basic components of a computer and high-performance computing cluster
- Diffentiate between running tasks in serial versus parallel
Computer components
When you bought your last computer, what did you look for? Probably some of the things listed below:
- Which operating system do I want?
- How much data storage do I need?
- Should I get a faster and more expensive solid state drive, or a standard spinning disk drive?
- Does the processor speed really matter? Maybe I’ll get the fastest one in my budget.
- How much memory do I need?
A lot of you probably only think about these things when you buy a new computer, but not every day. When using the cluster thinking about some of these computer components is essential to make sure you are using cluster resources effectively. In this lesson we will review some of these components and introduce you to some associated jargon.
CPU or Central Processing Unit
This is the component that processes everything you do on your computer. On my Macbook, the specs associated with this component are:
- Processor Name: Intel Core i7
- Processor Speed: 2.9 GHz
- Number of Processors: 1
- Total Number of Cores: 4
So, I have a processor with 4 “cores”, i.e. a “quad-core” processor. This means that my processor can do 4 distinct computations at the same time. Do you have a quad-core processor? Or maybe it is a duo-core (2 cores in 1 CPU)?
Data Storage
There are 2 options for built-in data storage
- HDD: Hard Disk Drive (spinning)
- SSD: Solid State Drive
This is a simple point, how much data can my computer store? It is measured in bytes, usually Gigabytes (GB) or Terabytes (TB). E.g. my laptop has 1 TB of storage on an HDD. What does your computer have?
Memory
Memory is a small amount of volatile or temporary information storage. This is distinct from the data storage we discussed in the previous point. It is an essential component of any computer, as this is where data is stored when some computation is being performed on it. If you have ever used R, note that all the objects in your environment are usually stored in memory until you save your environment.
E.g. my laptop has 16 GB of memory. How much memory do you have on your computer?
High-Performance Computing (HPC)
So how do all these components come into play when we talk about the cluster or high-performance computing environments?
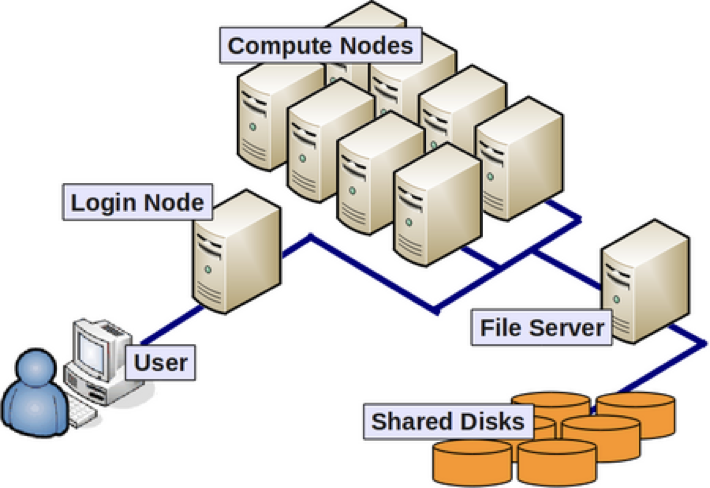
As we discussed in the first lesson, the above image shows us the many nodes (or computers) that make up a “cluster” of computers. Each individual node in an HPC environment is a lot more powerful than any laptop or desktop computer we are used to working with. What we mean by powerful here is that each of these nodes have:
- a lot more memory (temporary storage)
- many more, faster CPUs
- each of those CPUs has many more cores
E.g. A cluster “Node” that has eight “quad”-core CPUs, means that node has 32 cores (ability to process 32 computations at a time).
A note about data on the cluster: One thing that each of these powerful cluster nodes do not have is large amounts of data storage capability. Instead, all the data on a cluster is stored in a set of shared disks connected to all the nodes on the cluster. The data storage disks and nodes usually have very high-speed connectivity between them to avoid any data access lags.
Why use the cluster or an HPC environment?
- A lot of software is designed to work with the resources on an HPC environment and is either unavailable for, or unusable on, a personal computer.
- If you are performing analysis on large data files (e.g. high-throughput sequencing data), you should work on the cluster to avoid issues with memory and to get the analysis done a lot faster with the superior processing capacity. Essentially, a cluster has:
- 100s of cores for processing!
- 100s of Terabytes or even Petabytes of storage!
- 100s of Gigabytes of memory!
Parallelization
Point #2 in the last section brings us to the idea of parallelization or parallel computing that enables us to efficiently use the resources available on the cluster.
One input file
Let’s start with the most basic idea of processing 1 input file to generate 1 output (result) file. On a personal computer this would happen with a single core in the CPU.

On the cluster we have access to there are many cores on a single node, so in theory we could split up the analysis of a single file into multiple distinct processes and use as many cores to speed up the generation of an output file. This is called multithreading, i.e. using multiple threads or cores. As you can imagine, multithreading can speed up how fast the analysis is performed! In the example below, the input file is analyzed using 8 cores, likely resulting in an 8 fold speed up!
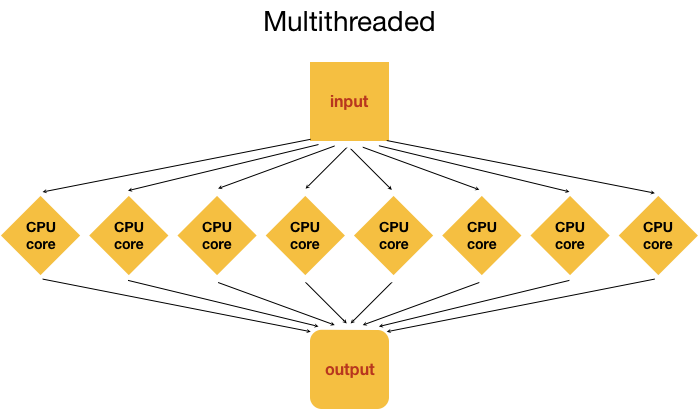
Note: Multithreading is done internally by analysis tools being employed, and not by manually splitting the input (except in very unusual circumstances).
Three input files
Now, what if we had 3 input files? Well, we could process these files in serial, i.e. use the same core(s) over and over again, as shown in the image below.
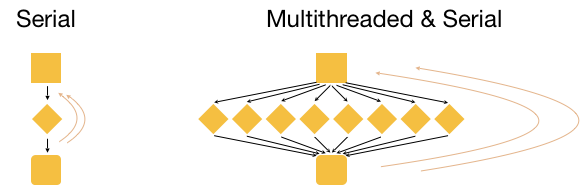
This is great, but it is not as efficient as multithreading each analysis, and using a set of 8 cores for each of the three input samples. This is actually considered to be true parallelization.

With parallelization, several samples can be analysed at the same time!
FASRC cluster
We will be going over the specifics of using the FASRC cluster in class. We will discuss:
- how to use software on the FASRC cluster
- how to request resources, like cores, memory, time etc. with the job scheduler Slurm (Simple Linux Utility for Resource Management)
- best practices (how to be a good cluster citizen)
- data storage limits
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.