Learning Objectives
- Describe the example RNA-seq experiment and its objectives.
- Demonstrate strategies for good data management and project organization.
The Dataset
The dataset we are using for this workshop is part of a larger study described in Kenny PJ et al., Cell Rep 2014. The authors are investigating interactions between various genes involved in Fragile X syndrome, a disease of aberrant protein production, which results in cognitive impairment and autistic-like features. The authors sought to show that RNA helicase MOV10 regulates the translation of RNAs involved in Fragile X syndrome.
Raw data
From this study we are using the RNA-seq data which is publicly available in the Sequence Read Archive (SRA).
NOTE: If you are interested in how to obtain publicly available sequence data from the SRA we have some materials on this linked here.
Metadata
In addition to the raw sequence data we also need to collect information about the data, also known as metadata. We are usually quick to want to begin analysis of the sequence data (FASTQ files), but how useful is it if we know nothing about the samples that this sequence data originated from?
Some relevant metadata for our dataset is provided below:
- The RNA was extracted from HEK293F cells that were transfected with a MOV10 transgene, MOV10 siRNA, or an irrelevant siRNA. (For this workshop we won’t be using the MOV10 knock down samples.)
- The libraries for this dataset are stranded and were generated using the standard Tru-seq prep kit (using the dUTP method).
- Sequencing was carried out on the Illumina HiSeq-2500 and 100bp single end reads were generated.
- The full dataset was sequenced to ~40 million reads per sample, but for this workshop we will be looking at a small subset on chr1 (~300,000 reads/sample).
- For each group we have three replicates as described in the figure below.

Implementing data management best practices
In a previous lesson we describe the data lifecycle and the different aspects to consider when working on your own projects. Here, we implement some of those strategies to get ourselves setup before we begin with any analysis.
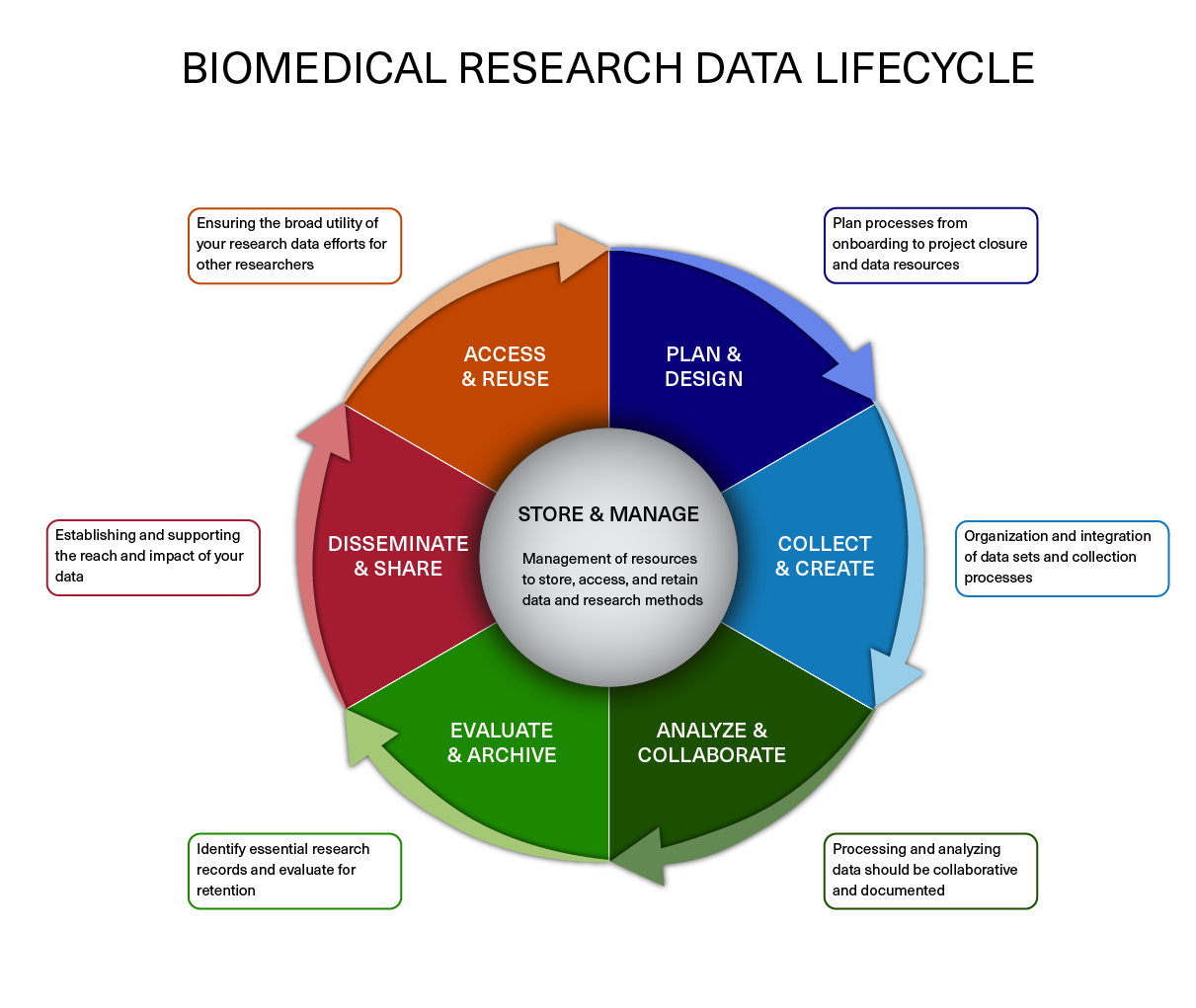
Image acquired from the Harvard Biomedical Data Management Website
Planning and organization
For each experiment you work on and analyze data for, it is considered best practice to get organized by creating a planned storage space (directory structure). We will start by creating a directory that we can use for the rest of the workshop. First, make sure that you are in your home directory.
$ cd
$ pwd
This should return /home/rc_training. Create the directory rnaseq and move into it.
$ mkdir rnaseq
$ cd rnaseq
Next, we will create a project directory and set up the following structure to keep our files organized.
rnaseq
├── logs
├── meta
├── raw_data
├── results
└── scripts
This is a generic structure and can be tweaked based on personal preference and the analysis workflow.
logs: to keep track of the commands run and the specific parameters used, but also to have a record of any standard output that is generated while running the command.meta: for any information that describes the samples you are using, which we refer to as metadata.raw_data: for any unmodified (raw) data obtained prior to computational analysis here, e.g. FASTQ files from the sequencing center. We strongly recommend leaving this directory unmodified through the analysis.results: for output from the different tools you implement in your workflow. Create sub-folders specific to each tool/step of the workflow within this folder.scripts: for scripts that you write and use to run analyses/workflow.
$ mkdir logs meta raw_data results scripts
File naming conventions
Another aspect of staying organized is making sure that all the directories and filenames for an analysis are as consistent as possible. You want to avoid names like
alignment1.bam, and rather have names like20170823_kd_rep1_gmap-1.4.bamwhich provide a basic level of information about the file. This link and this slideshow have some good guidelines for file naming dos and don’ts.
Documentation
In your lab notebook, you likely keep track of the different reagents and kits used for a specific protocol. Similarly, recording information about the tools used in the workflow is important for documenting your computational experiments.
- Make note of the software you use. Do your research and find out what tools are best for the data you are working with. Don’t just work with tools that you are able to easily install.
- Keep track of software versions. Keep up with the literature and make sure you are using the most up-to-date versions.
- Record information on parameters used and summary statistics at every step (e.g., how many adapters were removed, how many reads did not align)
- A general rule of thumb is to test on a single sample or a subset of the data before running your entire dataset through. This will allow you to debug quicker and give you a chance to also get a feel for the tool and the different parameters.
- Different tools have different ways of reporting log messages to the terminal. You might have to experiment a bit to figure out what output to capture. You can redirect standard output with the
>symbol which is equivalent to1> (standard out); other tools might require you to use2>to re-direct thestandard errorinstead.
README files
After setting up the directory structure it is useful to have a README file within your project directory. This is a plain text file containing a short summary about the project and a description of the files/directories found within it. An example README is shown below. It can also be helpful to include a README within each sub-directory with any information pertaining to the analysis.
## README ##
## This directory contains data generated during the Introduction to RNA-seq workshop
## Date:
There are five subdirectories in this directory:
raw_data : contains raw data
meta: contains...
logs:
results:
scripts:
Exercise
- Take a moment to create a README for the
rnaseq/folder (hint: usevimto create the file). Give a short description of the project and brief descriptions of the types of files you will be storing within each of the sub-directories.
Obtaining data
Let’s populate the rnaseq/ project with some data. The FASTQ files are located on the O2 cluster in the /n/groups space. Copy them over from the path shown below, into your raw_data directory:
$ cp /n/groups/hbctraining/unix_lesson/raw_fastq/*.fq ~/rnaseq/raw_data/
NOTE: When obtaining data from your sequencing facility, the data will not be stored on O2 and so a simple copy command (
cp) will not suffice. The raw sequence data will likely be located on another remote computer/server that is hosted by the sequencing facility and you will be given login credentials to access it. To copy it over you can use commands likersync,wgetorscp. These are all commands that can help securely copy the data over to the appropriate location on O2. We have some information linked here if you would like to learn more.
Now the structure of rnaseq/ should look like this:
rnaseq
├── logs
├── meta
├── raw_data
│ ├── Irrel_kd_1.subset.fq
│ ├── Irrel_kd_2.subset.fq
│ ├── Irrel_kd_3.subset.fq
│ ├── Mov10_oe_1.subset.fq
│ ├── Mov10_oe_2.subset.fq
│ └── Mov10_oe_3.subset.fq
├── README.txt
├── results
└── scripts
Okay, we are all set to begin the analysis!
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
- The materials used in this lesson were derived from work that is Copyright © Data Carpentry (http://datacarpentry.org/). All Data Carpentry instructional material is made available under the Creative Commons Attribution license (CC BY 4.0).
- Adapted from the lesson by Tracy Teal. Original contributors: Paul Wilson, Milad Fatenejad, Sasha Wood and Radhika Khetani for Software Carpentry (http://software-carpentry.org/)