Contributors: Mary Piper, Radhika Khetani
Approximate time: 55 minutes
Learning Objectives
- Become familiar with the Illumina sequencing technology
- Understanding how to use modules in the cluster environment
- Evaluate the quality of your sequencing data using FastQC
Quality control of sequence reads
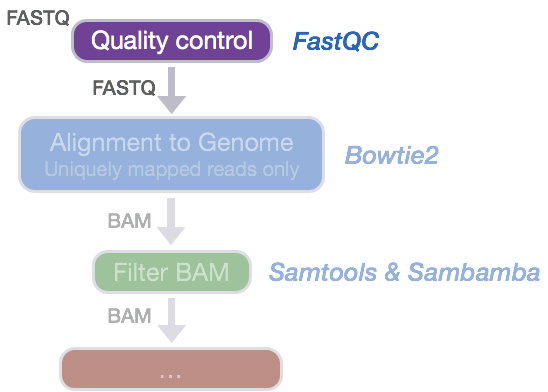
Now that we have our files and directory structure, we are ready to begin our ChIP-seq analysis. For any NGS analysis method, our first step in the workflow is to explore the quality of our reads prior to aligning them to the reference genome and proceeding with downstream analyses.
Understanding the Illumina sequencing technology
Before we can assess the quality of our reads, it would be helpful to know a little bit about how these reads were generated. Since our data was sequenced on an Illumina sequencer we will introduce you to their Sequencing by Synthesis methodology, however keep in mind there are other technologies and the way reads are generated will vary (as will the associated biases observed in your data).
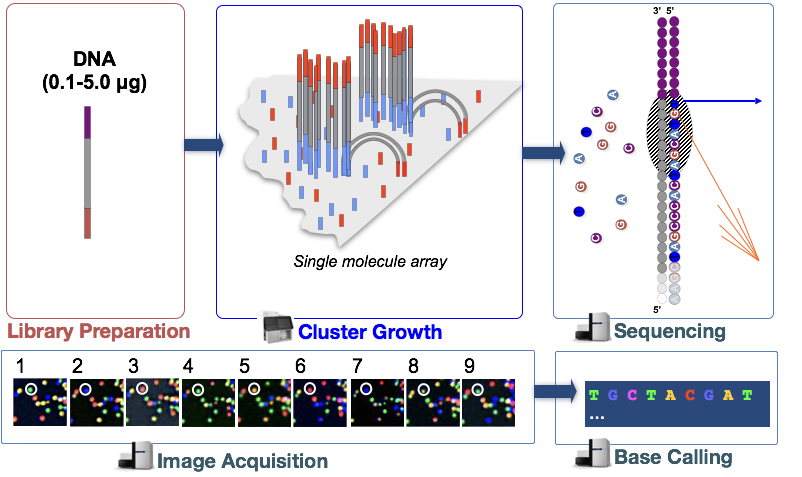
An animation of the Sequencing by Synthesis is most helpful (rather than reading through lines of text), and so we would like you to take five minutes and watch this YouTube video from Illumina.
Unmapped read data (FASTQ)
The FASTQ file format is the defacto file format for sequence reads generated from next-generation sequencing technologies. This file format evolved from FASTA in that it contains sequence data, but also contains quality information. Similar to FASTA, the FASTQ file begins with a header line. The difference is that the FASTQ header is denoted by a @ character. For a single record (sequence read) there are four lines, each of which are described below:
| Line | Description |
|---|---|
| 1 | Always begins with ‘@’ and then information about the read |
| 2 | The actual DNA sequence |
| 3 | Always begins with a ‘+’ and sometimes the same info in line 1 |
| 4 | Has a string of characters which represent the quality scores; must have same number of characters as line 2 |
Let’s use the following read as an example:
@HWI-ST330:304:H045HADXX:1:1101:1111:61397
CACTTGTAAGGGCAGGCCCCCTTCACCCTCCCGCTCCTGGGGGANNNNNNNNNNANNNCGAGGCCCTGGGGTAGAGGGNNNNNNNNNNNNNNGATCTTGG
+
@?@DDDDDDHHH?GH:?FCBGGB@C?DBEGIIIIAEF;FCGGI#########################################################
As mentioned previously, line 4 has characters encoding the quality of each nucleotide in the read. The legend below provides the mapping of quality scores (Phred-33) to the quality encoding characters. Different quality encoding scales exist (differing by offset in the ASCII table), but note the most commonly used one is fastqsanger.
Quality encoding: !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHI
| | | | |
Quality score: 0........10........20........30........40
Using the quality encoding character legend, the first nucelotide in the read (C) is called with a quality score of 31 and our Ns are called with a score of 2. As you can tell by now, this is a bad read.
Each quality score represents the probability that the corresponding nucleotide call is incorrect. This quality score is logarithmically based and is calculated as:
Q = -10 x log10(P), where P is the probability that a base call is erroneous
These probabaility values are the results from the base calling algorithm and dependent on how much signal was captured for the base incorporation. The score values can be interpreted as follows:
| Phred Quality Score | Probability of incorrect base call | Base call accuracy |
|---|---|---|
| 10 | 1 in 10 | 90% |
| 20 | 1 in 100 | 99% |
| 30 | 1 in 1000 | 99.9% |
| 40 | 1 in 10,000 | 99.99% |
| 50 | 1 in 100,000 | 99.999% |
| 60 | 1 in 1,000,000 | 99.9999% |
Therefore, for the first nucleotide in the read (C), there is less than a 1 in 1000 chance that the base was called incorrectly. Whereas, for the the end of the read there is greater than 50% probabaility that the base is called incorrectly.
Assessing quality with FastQC
Now we understand what information is stored in a FASTQ file, the next step is to examine quality metrics for our data.
FastQC provides a simple way to do some quality control checks on raw sequence data coming from high throughput sequencing pipelines. It provides a modular set of analyses which you can use to give a quick impression of whether your data has any problems of which you should be aware before doing any further analysis.
The main functions of FastQC are:
- Import of data from BAM, SAM or FastQ files (any variant)
- Providing a quick overview to tell you in which areas there may be problems
- Summary graphs and tables to quickly assess your data
- Export of results to an HTML based permanent report
- Offline operation to allow automated generation of reports without running the interactive application
Run FastQC
Let’s run FastQC on all of our files.
Change directories to the raw_data folder and check the contents
$ cd ~/chipseq/raw_data
$ ls -l
Before we start using any software, we either have to check if it’s available on the cluster, and if it is we have to load it into our environment (or $PATH). On the O2 cluster, we can check for and load tools using modules.
If we check which modules we currently have loaded, we should not see FastQC.
$ module list
NOTE: If we check our $PATH variable, we will see that the FastQC program is not in our $PATH (i.e. its not in a directory that unix will automatically check to run commands/programs).
$ echo $PATH
To find the FastQC module to load we need to search the versions available:
$ module spider
Then we can load the FastQC module:
$ module load fastqc/0.11.5
Once a module for a tool is loaded, you have essentially made it directly available to you like any other basic UNIX command.
$ module list
$ echo $PATH
FastQC will accept multiple file names as input, so we can use the *.fq wildcard.
$ fastqc *.fastq
Did you notice how each file was processed serially? How do we speed this up?
Exit the interactive session and once you are on a “login node,” start a new interactive session with 6 cores. Now we can use the multi-threading functionality of FastQC to speed this up by running 6 jobs at once, one job for one file.
$ exit #exit the current interactive session
$ srun --pty -c 6 -p interactive -t 0-12:00 --mem 1G --reservation=HBC2 /bin/bash #start a new one with 6 cpus (-n 6) and 1G RAM (--mem 1G)
$ module load fastqc/0.11.5 #reload the module for the new session
$ cd ~/chipseq/raw_data
$ fastqc -t 6 *.fastq #note the extra parameter we specified for 6 threads
How did I know about the -t argument for FastQC?
$ fastqc --help
Now, move all of the fastqc files to the results/fastqc directory:
$ mv *fastqc* ../results/fastqc/
FastQC Results
Let’s take a closer look at the files generated by FastQC:
$ ls -lh ../results/fastqc/
HTML reports
The .html files contain the final reports generated by fastqc, let’s take a closer look at them. Transfer the file for H1hesc_Input_Rep1_chr12.fastq over to your laptop via FileZilla.
Filezilla - Step 1
Open FileZilla, and click on the File tab. Choose ‘Site Manager’.
Filezilla - Step 2
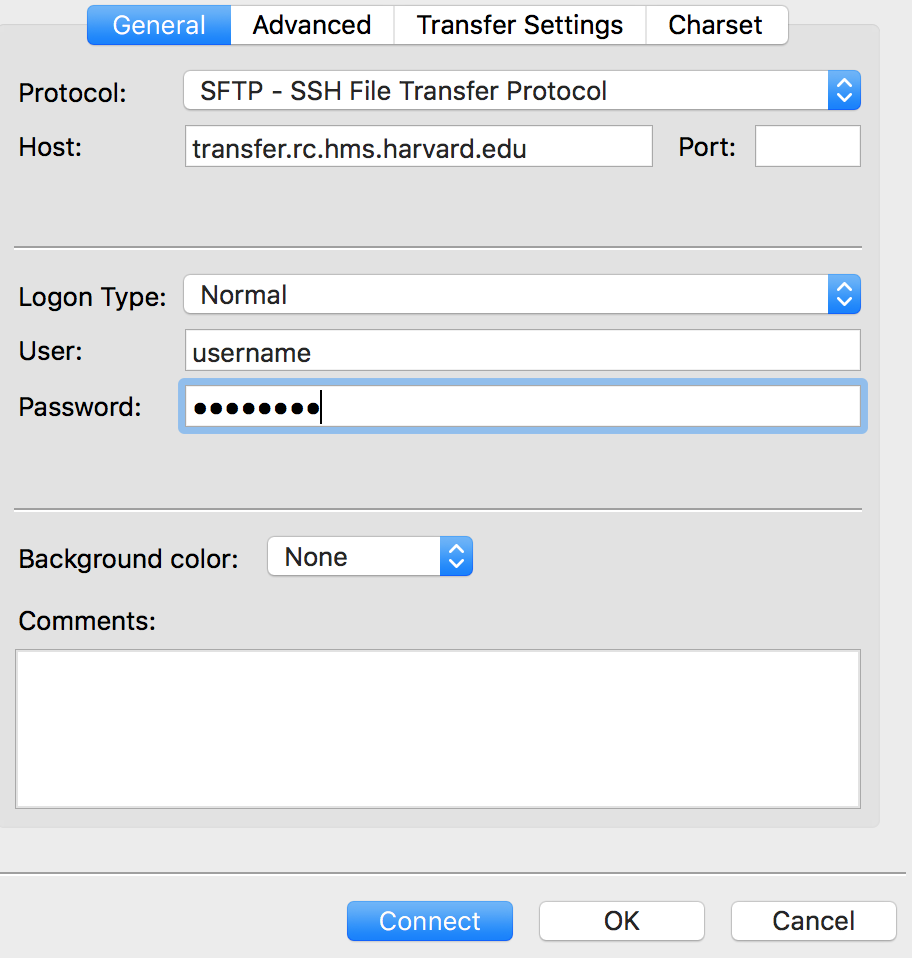
Within the ‘Site Manager’ window, do the following:
- Click on ‘New Site’, and name it something intuitive (e.g. O2)
- Host: transfer.rc.hms.harvard.edu
- Protocol: SFTP - SSH File Transfer Protocol
- Logon Type: Normal
- User: training_account
- Password: password for training_account
- Click ‘Connect’
The “Per base sequence quality” plot is the most important analysis module in FastQC for ChIP-seq; it provides the distribution of quality scores across all bases at each position in the reads. This information can help determine whether there were any problems at the sequencing facility during the sequencing of your data. Generally, we expect a decrease in quality towards the ends of the reads, but we shouldn’t see any quality drops at the beginning or in the middle of the reads.
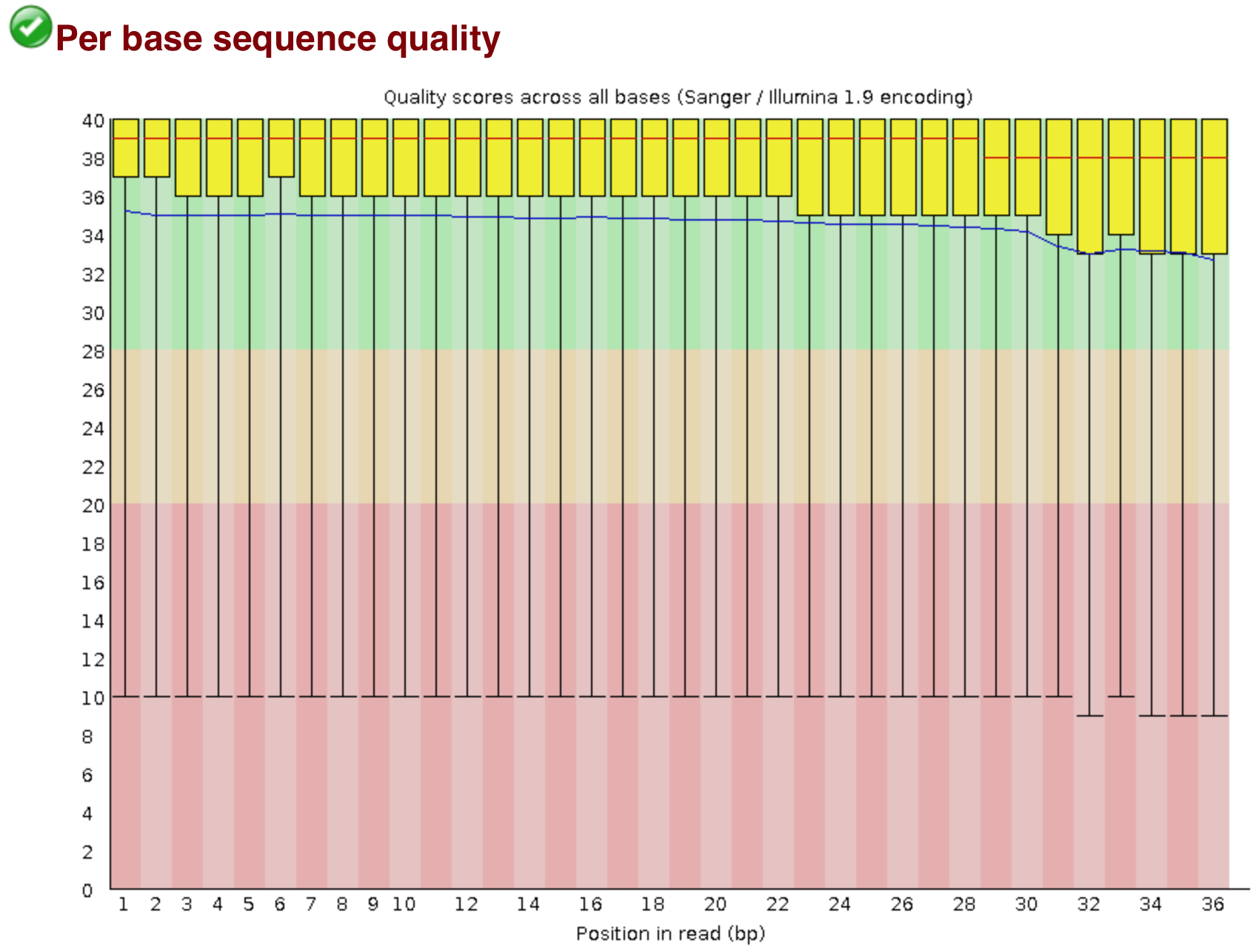
Based on the sequence quality plot, we see the majority of the reads have high quality, but the whiskers drop into the poor quality regions, indicating that a significant number of reads have low quality bases across the reads. The poor quality reads in the middle of the sequence would be concerning if this was our dataset, and we would probably want to contact the sequencing facility. However, this dataset was created artifically, so does not indicate a problem at the sequencing facility. Trimming could be performed from both ends of the sequences, or we can use an alignment tool that can ignore these poor quality bases at the ends of reads (soft clip).
This is the main plot explored for ChIP-seq, but if you would like to go through the remaining plots/metrics, FastQC has a really well documented manual page with more details about all the plots in the report. For ChIP-seq data, we recommend checking the following metrics:
- Per base sequence composition: You can expect to encounter read start sequence biases in this plot if fragmenting with transposases.
- Sequence duplication levels: This plot can help you get an idea of what proportion of your library corresponds to duplicates. Duplicates are typically removed (even if there is a chance that they are biological duplicates); therefore, if there is a large amount of duplication, the number of reads available for mapping and/or for peak calling will be reduced.
- Over-represented sequences: Over-represented sequences are either highly biologically significant or represent biases. With ChIP-seq you expect to see over-represented sequences in the IP sample because that’s exactly what you’re doing - enriching for particular sequences based on binding affinity. However, lack of over-represented sequences doesn’t mean you have a bad experiment. If you see over-represented sequences in the input, that usually reflects some bias in the protocol to specific regions.
We recommend looking at this post for more information on what bad plots look like and what they mean for your data. Also, FastQC is just an indicator of what’s going on with your data, don’t take the “PASS”es and “FAIL”s too seriously.
We also have a slidedeck of error profiles for Illumina sequencing, where we discuss specific FASTQC plots and possible sources of these types of errors.
This lesson has been developed by members of the teaching team at the Harvard Chan Bioinformatics Core (HBC). These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.